Paper Review/Object Detection
[Paper Review - Object Detection] 4. YOLOv1
_JSP_
2023. 1. 25. 23:03
1. YOLOv1 요약
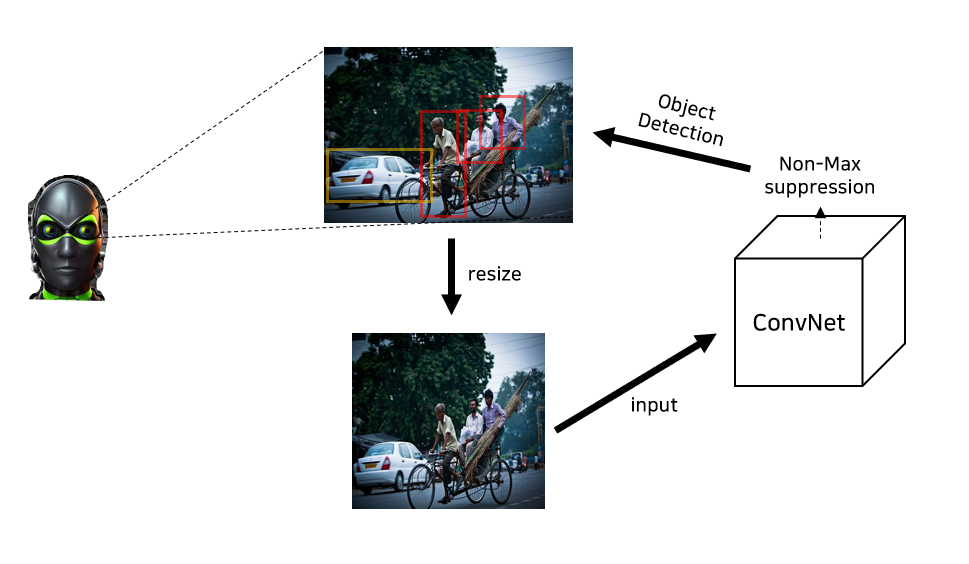
1) YOLOv1의 Detection System
2) YOLOv1의 장단점
(1) 장점
- One-Stage Object Detection
- 45 fps로 빠르다. => Real time object detection에 적합하다.
- 물체에 대해서 더 잘 일반화를 한다.
- 배경에 대해서 잘못 예측하는 경우가 더 적다.
(2) 단점
- 더 많은 Localization Error을 가진다.
2. YOLOv1의 용어정리
1) Leaky ReLU
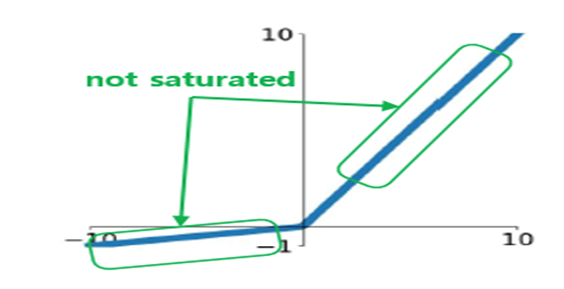
- ReLU에서 일부 뉴런이 활성화되지 않는 문제를 개선
-
x ≤ 0에 대해서, 0.01x를 적용
2) HSV color space
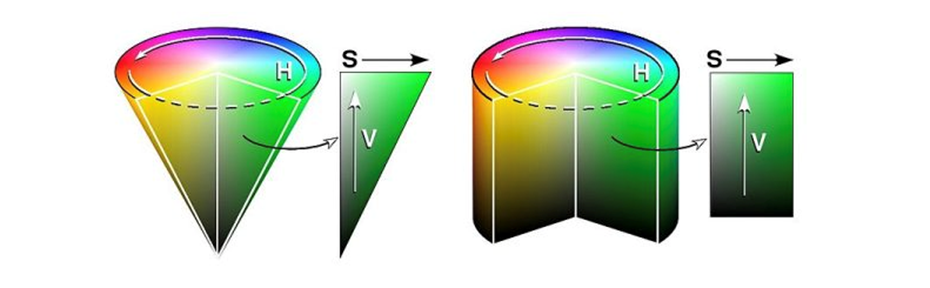
-
(H, S, V)의 좌표로 색을 표현하는 방법
-
H(Hue) : 색상, 색의 종류 (0~179)
-
S(Saturation) : 채도, 색의 탁하고 선명한 정도(0~255)
-
V(Value) : 명도, 빛의 밝기(0~255)
-
-
원기둥 또는 원뿔 모양으로 표현
3) Darknet framework

-
Joseph Redmon이 독자적으로 개발한 neural network framework
-
C, CUDA로 작성된 Open source
-
YOLO, AlexNet, VGG-16, Resnet, DenseNet 등의 Model 지원
3. Unified Detection
1) YOLOv1의 Detection System
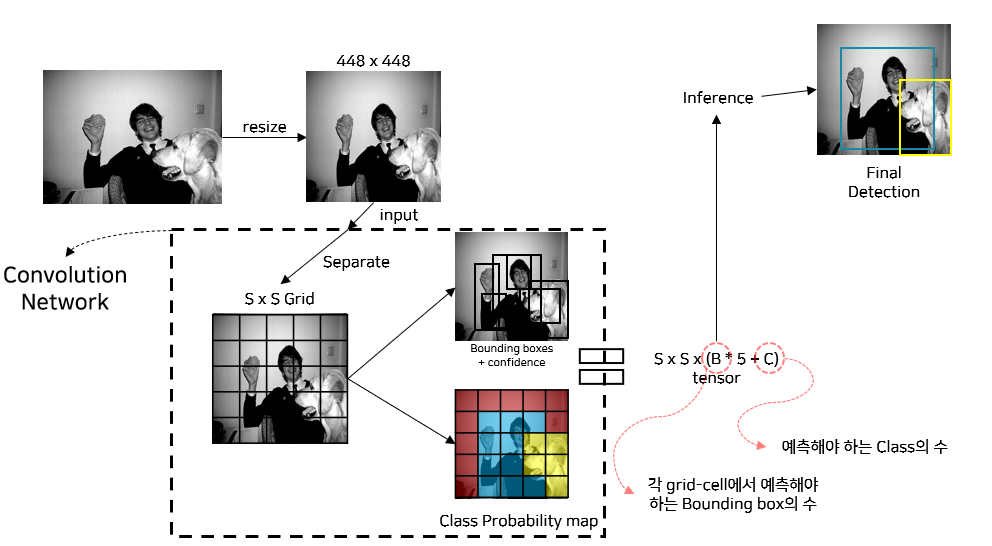
2) YOLOv1의 Convolution Network
3) YOLOv1의 Output
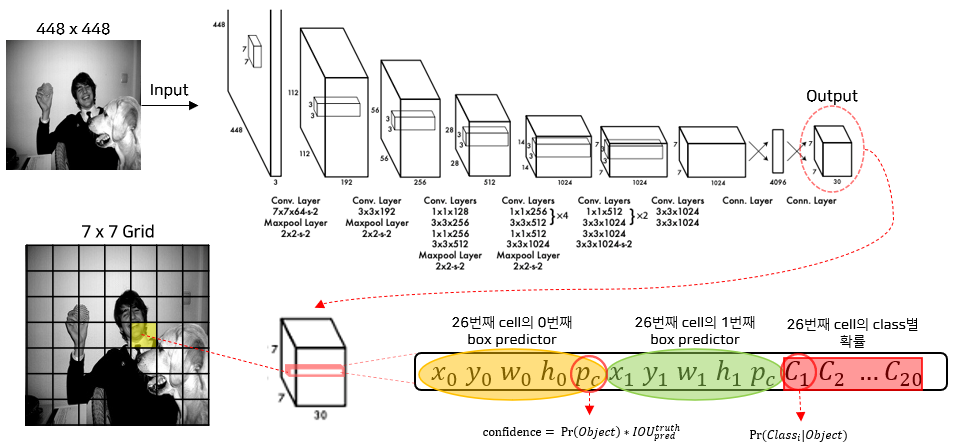
- S = 7, B = 2, C = 20으로 설정
4) YOLOv1의 Detection System 요약
- Detection System
- Image를 S x S grid-cell로 분리
- 각 grid-cell은 B개의 box predicter가 존재하고, box predicter는 (x, y, w, h) + confidence를 예측
-
각 grid-cell은 C개의 class에 대한 확률 값을 가진다.
- Network Design
-
GoogleNet에서 3 x 3 conv layers – 1 x 1 conv layers를 추가
-
24개의 convolutional layers – 2개의 fully connected layer의 구조.
-
5) YOLOv1의 학습
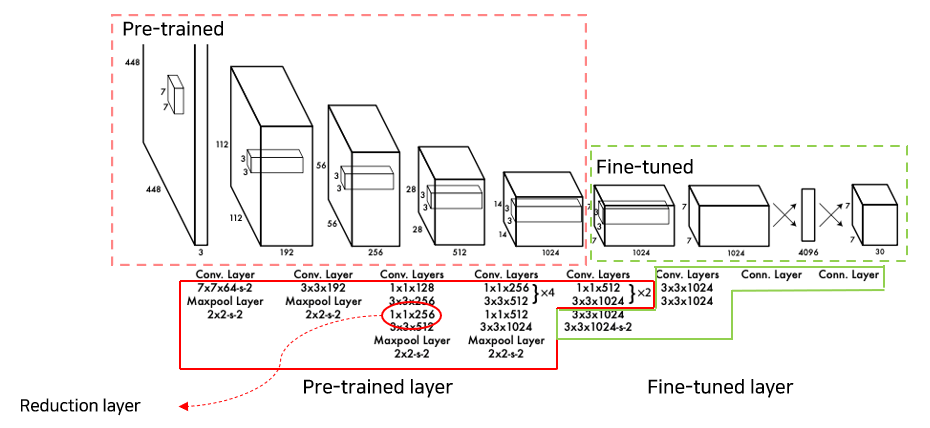
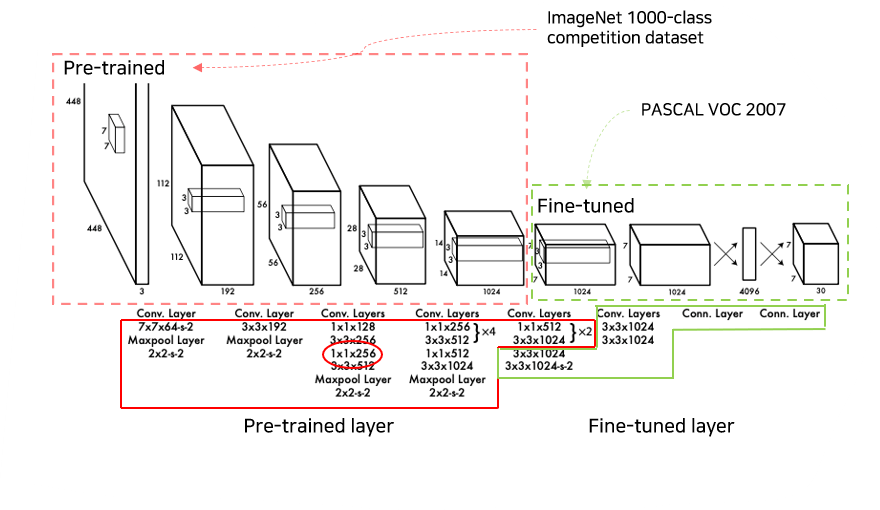
(1) Pre-trained layer 및 Fine-tuned layer
(2) Layer 세부사항
- Pre-trained layers
-
학습데이터 : 1000 – ImageNet 1000-class competition dataset
-
입력 형태 : 224 x 224
-
Network 구조 : 20 Conv layers(+ average-pooling layers) + fully connected layer
-
-
Fine-tuned layers
- Network 구조 : 4 Conv layers + fully connected layer1 + fully connected layer2
- 4 Conv layers + fully connected layer1
- Random Initialize
- 입력 형태 : 448 x 448
- fully connected layer2
- Class probability & box coordinates 예측 -> w, h는 이미지의 너비, 높이에 정규화, x, y는 grid cell location의 offset
- linear activation 사용
- 4 Conv layers + fully connected layer1
- Network 구조 : 4 Conv layers + fully connected layer1 + fully connected layer2
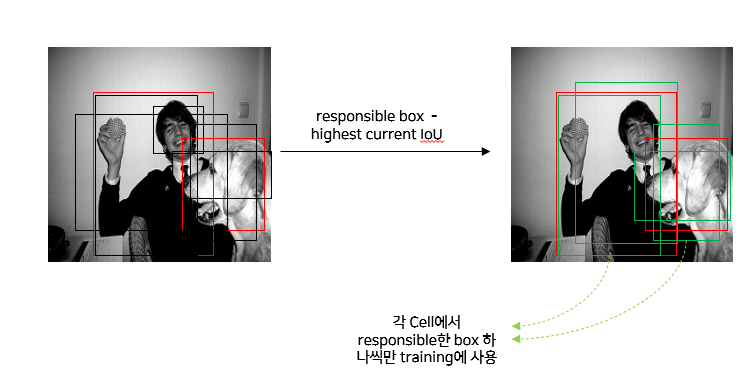
(3) 학습시 예측한 Bounding box 사용
(4) Multi-part Loss function
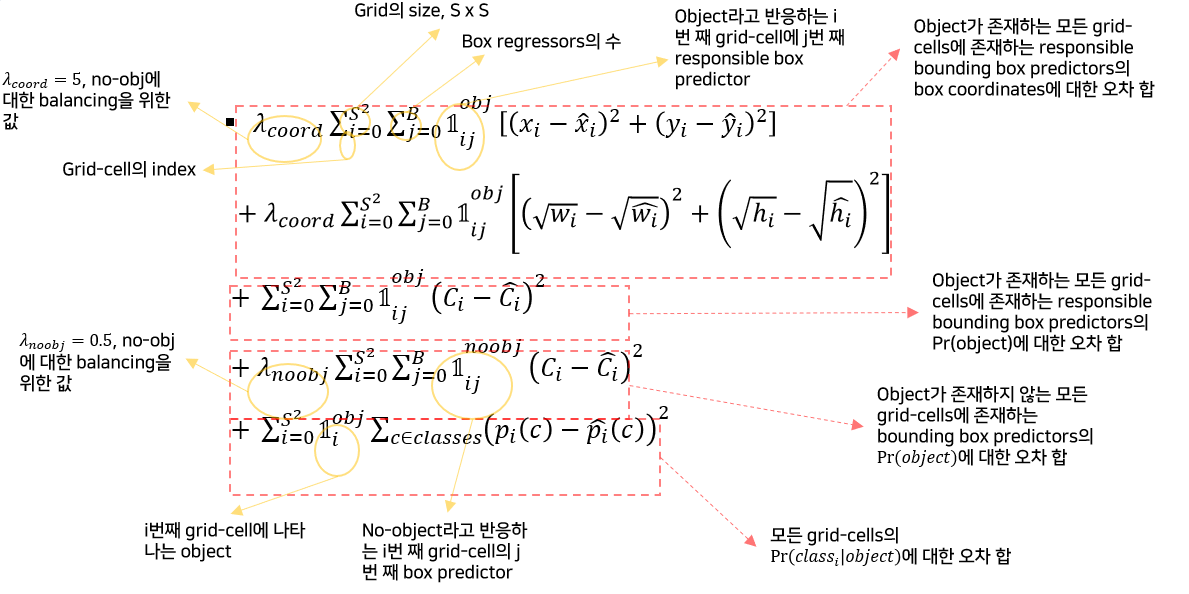
(5) 학습 정보
-
Parameters
-
Epochs : 135
-
Batch size : 64
-
Momentum : 0.9
-
Decay : 0.0005
-
-
Learning rate schedule
- first epochs는 10^(-3) →10^(-2) 로 서서히 증가 => Gradient exploding 방지
- 75 epochs까지는 10^(-2) 로, 이후 30 epochs까지는 10^(-3), 마지막 30 epochs는 10^(-4)로 학습 => 수렴에 가까워질 때, 세밀한 조정
-
Avoid overfitting
-
dropout : 0.5
-
extensive data augmentation
-
HSV color space에서 1.5배까지 exposure과 saturation을 무작위로 조정
-
6) YOLOv1 추론
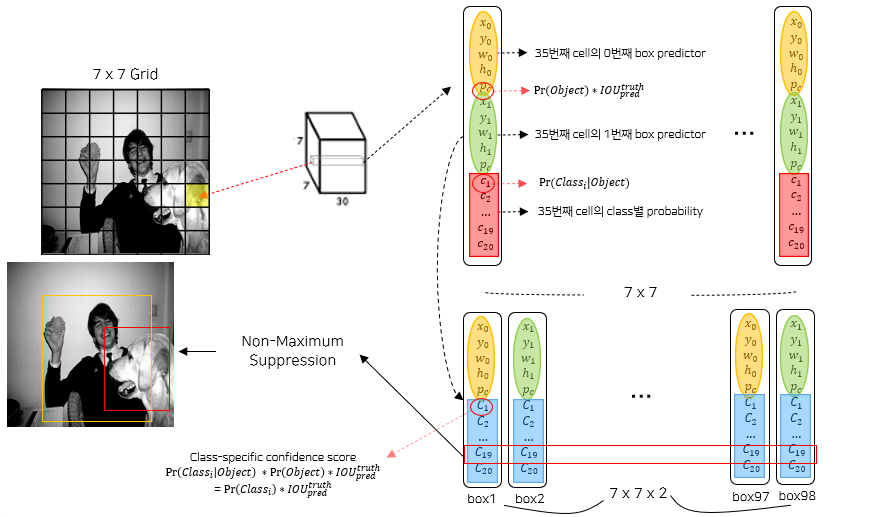
- S = 7, B = 2, C = 20으로 설정
7) YOLOv1의 한계
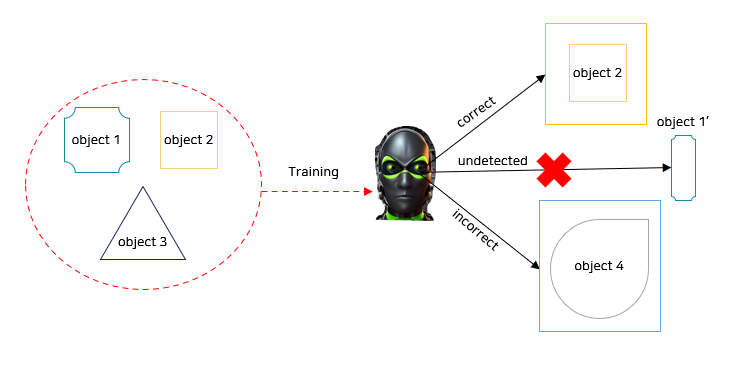
(1) 비정상 객체에 대한 탐지 어려움
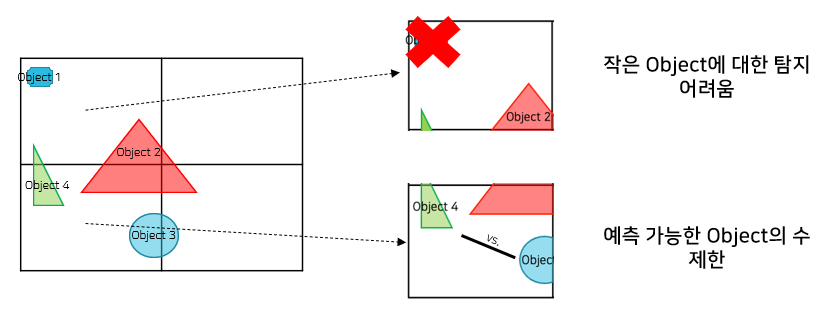
(2) 작은 객체에 대한 탐지 어려움
8) YOLOv1의 강점
-
One-Stage Object Detection
-
Single-stage pipeline
-
Simple architecture
-
Fewer region proposals
-
No required additional classification
4. 실험
1) 다른 Real-time Detection 모델과 비교
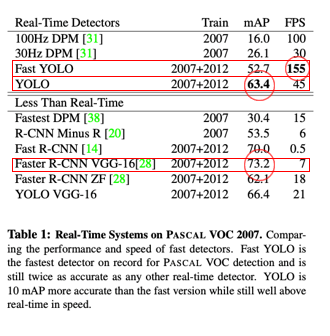
- 다른 모델에 비해 빠른 속도와 준수한 정확도를 지닌다.
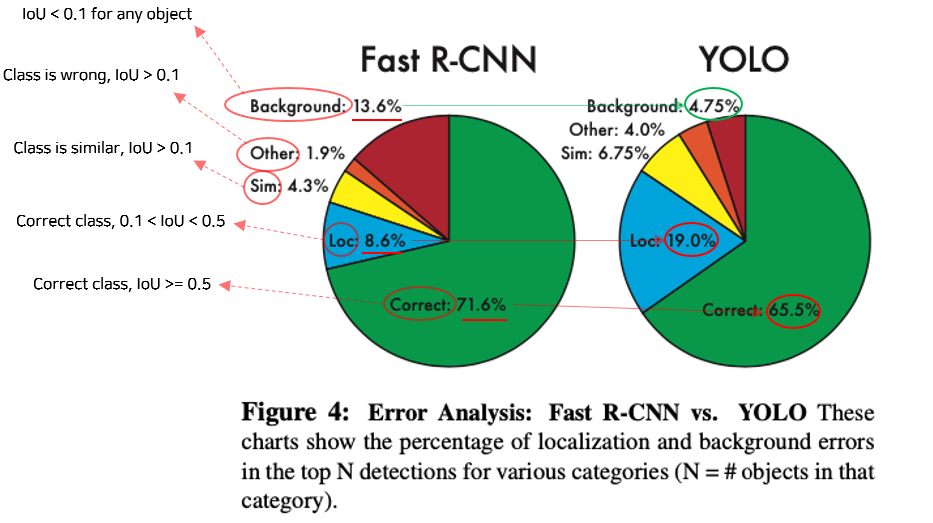
2) VOC 2007 데이터셋에 대한 Error 분석(Fast R-CNN과 비교)
3) Fast R-CNN과 YOLO을 결합한 경우의 성능 실험
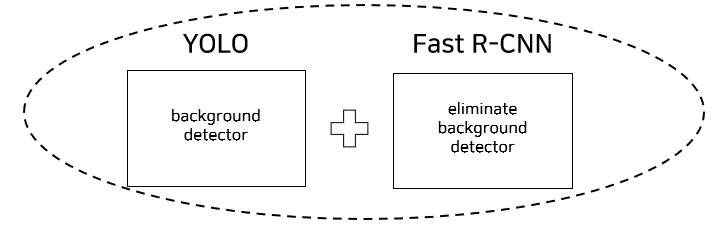
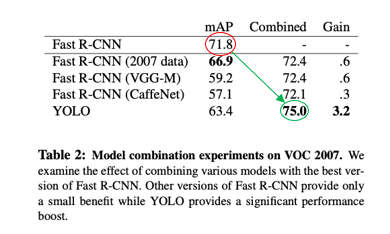
- 결합한 경우 성능이 더 향상된다.
4) VOC 2012 데이터셋에 대한 성능 실험
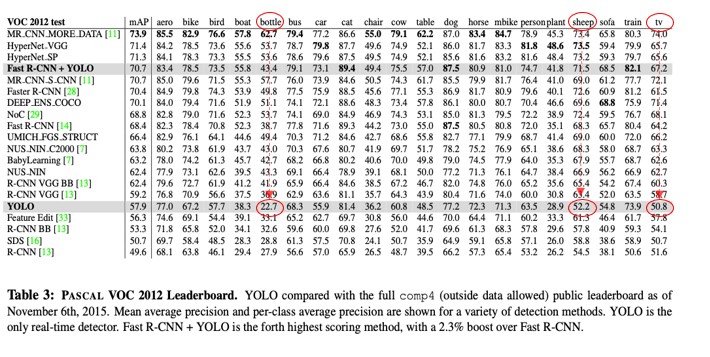
- 작은 객체에 대한 탐지 성능이 다른 모델에 비해 떨어진다.
- 유사한 객체가 존재하는 객체에 대해서도 성능이 떨어진다.
5) Generalizability 실험
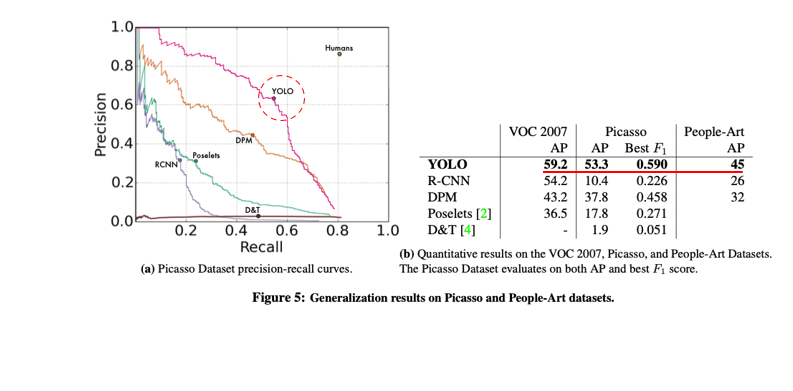
- Domain이 다른 객체에 대해서도 좋은 탐지 성능을 보인다 => 일반화 가능성이 존재
< Reference >
[1] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. ou Only Look Once: Unified, Real-Time Object Detection. IN CSCV, 2016
[2] 이윤승. https://www.youtube.com/watch?v=O78V3kwBRBk