
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Linux build
- 논문분석
- TensorFlow Object Detection 사용예시
- Towards Deep Learning Models Resistant to Adversarial Attacks
- TensorFlow Object Detection Model Build
- 개발흐름
- Git
- 논문 분석
- InstructPix2Pix
- paper review
- DOTA dataset
- TensorFlow Object Detection API install
- TensorFlow Object Detection Error
- VOC 변환
- Object Detection Dataset 생성
- Carla
- 사회초년생 추천독서
- 리눅스 빌드
- DACON
- Branch 활용 개발
- AI Security
- 크롤링
- 커스텀 애니메이션 적용
- 기능과 역할
- CARLA simulator
- Custom Animation
- Docker
- object detection
- Paper Analysis
- 객체 탐지
- Today
- Total
JSP's Deep learning
[Paper Review - AI Security] 1. Explaining And Harnessing Adversarial Examples(Digital Attack) 본문
[Paper Review - AI Security] 1. Explaining And Harnessing Adversarial Examples(Digital Attack)
_JSP_ 2023. 1. 15. 14:251. Adversarial Examples 요약
- "Adversarial Examples"는 Model의 선형성(Linear nature)의 취약점을 이용한 공격 기법이다.
- "FGSM(Fast Gradient Sign Method)"을 통해서 Adversarial Examples을 생성한다.
- "Adversarial Training"을 통해서 "Adversarial Example"에 대해 Model을 Robust하게 한다.
2. 주요 용어
1) Softplus Function
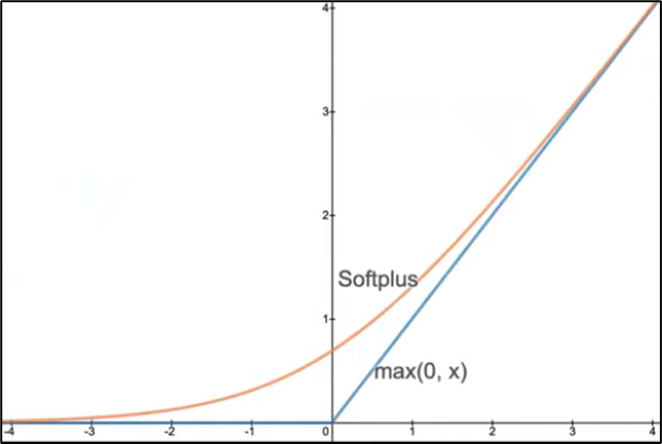
- log(1+exp(x))로 정의된다.
- ReLU와 비슷하지만 ReLU는 x < 0에 대해서 0으로 처리하는 반면에 SoftPlus는 조금 더 Smooth하게 0으로 수렴하게 한다.
2) Maxout Function

- 활성화 함수를 piecewise linear function이라고 가정했을 때, 각 구간별 최댓값만 취하는 함수
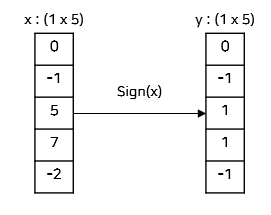
3) Sign Function
- y=sign(x)에 대해서 y는 x와 동일한 크기의 배열을 반환한다.
- y의 각 요소는 다음과 같이 결정된다.
- x > 0이면, 1
- x = 0이면, 0
- x < 0이면, -1
- 예시) (1 x 5)인 vector에 대해서 Sign function을 취할 때의 y 값
4) Saturating과 Non-Saturating

- Saturating : weight의 업데이트가 일어나지 않는 부분
- Non-Saturating : weight의 업데이트가 일어나는 부분
5) Shallow neural network

- Network의 구조가 입력 - 은닉 - 출력 3가지 계층으로 되어있는 얕은 신경망
- 출력 계층은 Fully connected layer을 사용한다.
3. 본문 분석
1) 선형적 설명
(1) Adversarial Example이란?

- 원본 이미지에 𝝐만큼의 작은 노이즈(Adversarial perturbation)을 섞어서 Loss을 증가시켜서 Mis-classification을 유발하는 적대적인 Example
(2) Digital Image의 특성을 이용한 Adversarial Example

- 디지털 이미지의 특성
- 각 Pixel을 8-bits로 표현하며 0~255 외의 값은 버린다.
- Adversarial perturbation은 이미지 또는 저장장치가 버리지 못하는 최소값을 가지므로, 이를 이미지에 섞으면 Model은 다른 값으로 보고 Mis-Classification을 하지만, 사람의 눈에는 구분되지 않는다.
(3) Adversarial Example의 수식적 정의
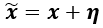
- 의미

- 해석
- Adversarial Example = Normal Example + Adversarial perturbation
- 여기서 ||η||∞< ϵ 로 Adversarial perturbation은 ϵ보다 작다. (ϵ은 Adversarial Perturbation의 크기를 조정하는 임의의 상수)
(4) Sign function을 통해서 loss을 증가시키는 원리
- Adversarial perturbation과 weight vector의 dot product
- 수식

- 다음과 같이 정의된 수식에서 η = sign(w)을 적용하여 값을 증폭시킨다.

- 예시)
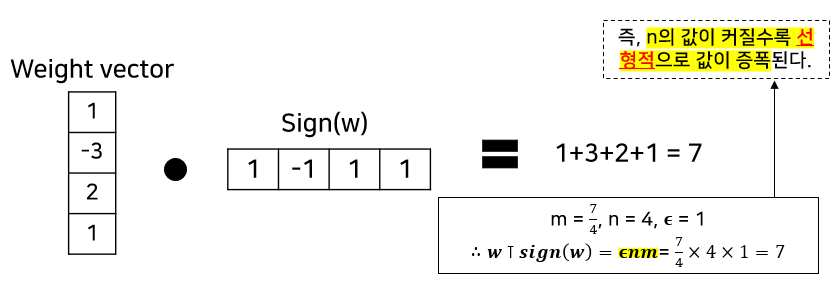
2) 선형적이지 않은 Model의 선형적인 특성에 의한 perturbation 발생
(1) Non-Linear Model의 Linearity nature
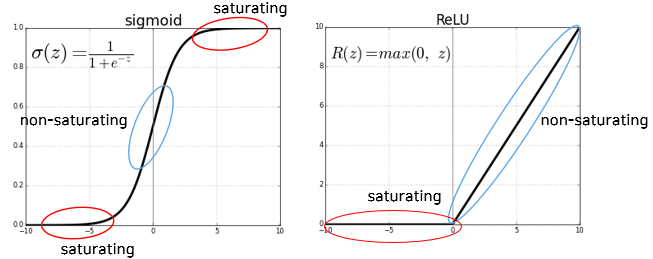
- LSTM, ReLU, Maxout Network는 모델의 최적화(학습)을 쉽게하기 위해서 의도적으로 Linearity하게 설계한다.
- Sigmoid function도 non-linear한 함수이지만, Linearity한 Non-saturating 부분에 집중하는 경향이 있어 Linearity을 가지게 된다.
(2) Fast Gradient Sign Method(FGSM)

- 모델의 Linear nature에 대한 취약점을 이용하여 Adversarial perturbation을 생성하는 Adversarial Attack
- 수식 정의

- 즉, Output에 대한 Loss을 증폭시키는 Adversarial Perturbation을 생성한다.
3) Adversarial Training
(1) Adversarial Training 정의
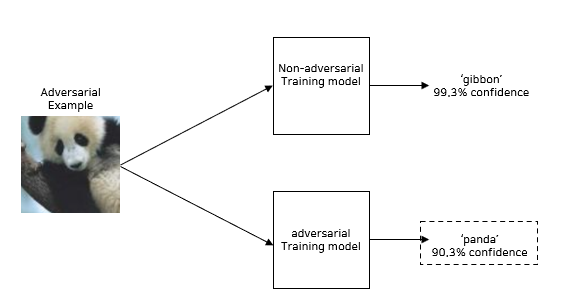
- Adversarial Training은 Adversarial Example에 대한 Robustness을 향상시키는 Adversarial Defence 기법이다.
(2) Adversarial Training의 Loss function
- Adversarial Training의 Loss function 구하는 방법
- Linear model의 Loss function에 대한 미분 값 구하기
- 미분 값에 대해서 Sign function 적용하여 η(Adversarial perturbation) 값을 구한다.
- x ̃=x+η 이므로, x 대신 x + η 값을 대입하여 Adversarial Training의 Loss function을 구한다.
- Linear Model의 Loss function 미분 및 Sign function 적용
- Linear Model의 Loss function

- Softplus function

- Linear Model의 weight function
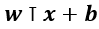
- Linear Model의 Loss function 미분 및 Sign function 적용

2. Adversarial Training의 Loss function 구하기

(3) Adversarial Training Loss function vs. Weight decay L1 Loss function
- Weight decay L1 Loss function
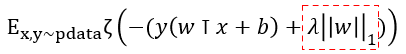
- Adversarial Training Loss function

- 차이점
- Weight decay L1 Loss function은 +λ||w||1에 의해서 패널티가 더해지는 방식이기 때문에 Adversarial perturbation에 민감하게 된다.
- Adversarial Training Loss function은 -ϵ||w||1에 의해서 패널티가 상쇄되는 방식이기 때문에 Adversarial perturbation에 둔감해진다.
(4) Deep learning Model(Non-linear model)에 대한 Adversarial Training
- 수식
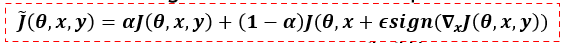
- Normal Example에 대한 Loss

- Adversarial Example에 대한 Loss

- 해석
- Normal Example에 대한 Loss와 Adversarial Example에 대한 Loss을 α : 1 - α의 비율로 계산
- 본문에서는 α=0.5로 설정하였다.
4. 실험
1) ϵ 값에 따른 FGSM 적용
- ϵ = 0.25
- Shallow softmax classifier : Average Confidence 79.3% - 99.9% error rate (MNIST Dataset 학습)
- Maxout Network : Average Confidence 97.6% - 89.4% error rate (MNIST Dataset 학습)
- ϵ = 0.1
- Convolution maxout Network : Average Confidence 96.6% - 87.15% error rate(CIFAR-10)
- 실험을 통한 저자의 결론
- Single Alogorithms(FGSM)으로 High-Confidence올 High-Error rate가 유발되는 이유는 모델의 Linearity 때문이다.
2) FGSM 적용 예시(MNIST dataset)

- Adversarial perturbation이 적용되니 Data가 훼손되는 모습을 확인할 수 있다.
3) Adversarial Training 적용 vs. Adversarial Training 미적용 Filters 시각화

- Error rate 변화
- Adversarial Training 미적용(+ Dropout 적용) : 89.4% Error rate
- Adversarial Training 적용 : 17.9% Error rate
- 해석
- Adversarial Training을 적용하면, Adversarial perturbation에 대한 저항력이 생긴다.
- 그러나 모든 Adversarial perturbation에 대해서 저항력이 생기는 것은 아니며, 몇몇 Adversarial example에 대해서는 High-confidence로 잘못 예측한다.
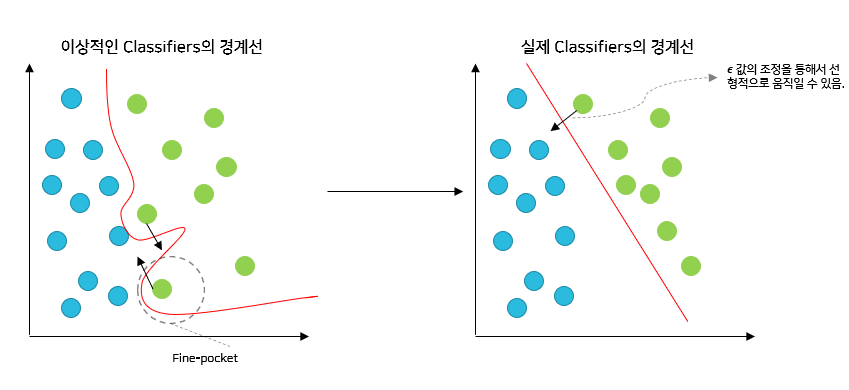
4) Adversarial Example의 Generalization 실험

- ϵ 값을 -15 ~ 15로 했을 때, argument to softmax의 값의 변화 및 Data의 변화를 시각화
- 해석
- ϵ 값의 변화에 따른 argument to softmax의 변화가 매우 선형적으로 나타나는 것을 확인할 수 있다.
- 해당 결과를 통해서 Adversarial Example은 특정 범위에만 존재하는 것이 아니라 선형적으로 매우 넓은 범위에 존재하는 것을 알 수 있다. 즉, Fine-Pocket에만 존재하지 않는다.
- 예시) 실험을 통해 알아낸 선형적 특성
5. 논의
1) 모델 학습 시, Adversarial Example과 Normal Example을 구분하도록 학습하면 Model의 Robustness가 향상되지 않을까?
- MNIST Dataset으로 실험
- Classification 성능이 뛰어난 Model에 대해서 Adversarial Example과 Normal Example을 판별하도록 학습
- 결과
- 97.5% Error rate로 효과가 없다.
2) 여러 모델을 앙상블한다면 Adversarial Example에 대한 저항력이 올라가지 않을까?
- MNIST Dataset으로 실험
- 12개의 maxout model을 앙상블
- 87.9% Error rate로 효과가 있으나, 미비한 효과이다.
6. 결론
- 딥러닝 모델의 Linear한 Nature 때문에 Adversarial Example이 발생한다.
- 딥러닝 모델의 Linear한 Nature 때문에 Adversarial Example이 Generalization을 갖는다.
- 대부분의 모델이 ReLU, Gradient descent 기반으로 학습되기 때문에 Linear Nature을 갖게된다.
- Softmax만으로 판단하는 것이 아닌 Local Boundary을 지정하여 판단하도록 딥러닝 모델을 Locally stable하게 설계할 필요가 있다.
< Reference >
[1] lan J. Goodfellow, Jonathon Shlens & Christian Szegedy. Explaining And Harnessing Adversarial Examples. IN ICLR, 2015.
[2] 나동빈, https://www.youtube.com/watch?v=99uxhAjNwps, YouTube.

