
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 리눅스 빌드
- 논문분석
- DACON
- Branch 활용 개발
- paper review
- Towards Deep Learning Models Resistant to Adversarial Attacks
- TensorFlow Object Detection 사용예시
- Object Detection Dataset 생성
- 기능과 역할
- Paper Analysis
- 객체 탐지
- CARLA simulator
- TensorFlow Object Detection Model Build
- Linux build
- 크롤링
- 사회초년생 추천독서
- Docker
- DOTA dataset
- Git
- Custom Animation
- 커스텀 애니메이션 적용
- object detection
- VOC 변환
- TensorFlow Object Detection API install
- 개발흐름
- AI Security
- TensorFlow Object Detection Error
- Carla
- InstructPix2Pix
- 논문 분석
- Today
- Total
JSP's Deep learning
[Crawling Practice] 2. 프리스타일2/자유게시판 크롤링 본문
오늘 해볼 크롤링은 프리스타일 2라는 게임 홈페이지의 자유게시판~!
유저수가 많지 않은 게임이라 아는 사람이 별로 없는 게임이지만,
나의 학창시절을 책임져준 게임...
사실해보고 싶은 이유는 추억인 부분도 있고, 이 게임이 운영을 정말 못했던 터라... 운영진들이 자유게시판을 좀 분석해봤으면 어떨까 하는 마음으로 내가 대신 데이터를 수집한다~!
이번에는 크롤링의 코드를 분리해서 분석해보고자 한다.
1. 패키지 로드
import pandas as pd
import numpy as np
import chromedriver_autoinstaller
from selenium import webdriver # 라이브러리(모듈) 가져오라
from selenium.webdriver import ActionChains as AC
from tqdm import tqdm
from tqdm.notebook import tqdm
import re
from time import sleep
import time
from tqdm import tqdm_notebook
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')패키지에 대한 설명은 저번에 했으니 생략하도록 한다.
2. 크롬 웹 드라이버 선언
options = webdriver.ChromeOptions()
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path, options=options)웹 드라이버를 사용하기 위해 크롬 드라이버 객체를 선언한다.
3. 프리스타일2 사이트 접속
# 구글 창 띄우기
driver.get("http://google.com")
time.sleep(3)
# 프리스타일2 검색
element = driver.find_element_by_css_selector('.gLFyf.gsfi')
element.send_keys("프리스타일2")
element.submit()
time.sleep(1)
# 프리스타일2 사이트 접속
driver.find_element_by_css_selector(".LC20lb.MBeuO.DKV0Md").click()
time.sleep(1)위의 코드를 보면서,
'왜, 프리스타일2 URL로 바로 접속하지 않고 구글에서 검색하면서 들어가는 거지?'라는 의문점이 사실 예전에 들었었는데, 그 이유는 크롤링을 차단하는 시스템을 회피하기 위함이다.
원리는 크롤러가 거쳐왔던 사이트를 로그에 남김으로써 봇으로 인식되지 않게 하는 것이다!
--
element들은 기본적으로 css_selector 방식을 이용하여 찾았다.
4. 프리스타일2 홈페이지 내의 커뮤니티에 접속
# 커뮤니티 클릭
driver.find_element_by_css_selector(".sub_menu.nav_community").click()
time.sleep(1)
5. 본격 크롤링에 앞서서 필요 변수 선언
page_num = 10 # 크롤링할 페이지 설정
board_num = 4 # 게시글이 시작하는 위치를 표시
title_list = [] # 제목을 담을 리스트
content_num_list = [] # 글 번호를 담을 리스트
content_writer_list = [] # 작성자를 담을 리스트
content_date_list = [] # 날짜를 담을 리스트
content_list = [] # 내용을 담을 리스트
6. for문을 이용한 크롤링
for page in tqdm_notebook(range(1, page_num)): # 지정한 페이지 수만큼 반복
for i in range(board_num, 14): # 게시판의 글을 차례대로 지정
try:
# 게시글 들어가기
driver.find_element_by_css_selector(f"#contents > table > tbody > tr:nth-child({i}) > td:nth-child(3) > a").click()
time.sleep(1)
# 제목 추출
title = driver.find_element_by_css_selector(".title").text
# 글의 상세정보가 분리되지 않음 => 글번호, 작성자, 작성날짜 추출과정을 거침
date = driver.find_element_by_css_selector(".info-list")
info_list = date.text.split()
content_number = info_list[0]
content_number = re.sub('[^0-9]', '', content_number)
content_writer = info_list[2]
content_date = info_list[4] + ' ' + info_list[5]
# 내용 추출 => 내용의 끝에 좋아요 싫어요를 삭제
content = driver.find_element_by_css_selector(".con-area").text[:-11]
# 목록으로 나가기
driver.execute_script("window.scrollTo(0, 500)")
driver.find_element_by_css_selector(".utils .btn-type02").click()
driver.execute_script("window.scrollTo(0, 600)")
time.sleep(1)
# 리스트에 저장
title_list.append(title)
content_num_list.append(content_number)
content_writer_list.append(content_writer)
content_date_list.append(content_date)
content_list.append(content)
except:
pass
# 다음 페이지
driver.execute_script("window.scrollTo(0, 50000)")
driver.find_element_by_xpath(f'//*[@id="contents"]/div[2]/p/a[{page}]')
time.sleep(1)
코드를 보면 알겠지만
css_selector 방식을 사용할 때도 있고,
xpath 방식을 사용할 때도 있다.
이는 각 요소마다 편한 방법이 다르니 적절하게 혼용하여 사용하도록 한다!
7. 크롤링된 데이터를 데이터 프레임으로 구축
df = pd.DataFrame({'글번호' : content_num_list, '제목' : title_list, '작성날짜' : content_date_list, '작성자' : content_writer_list
, '내용' : content_list})
df.head()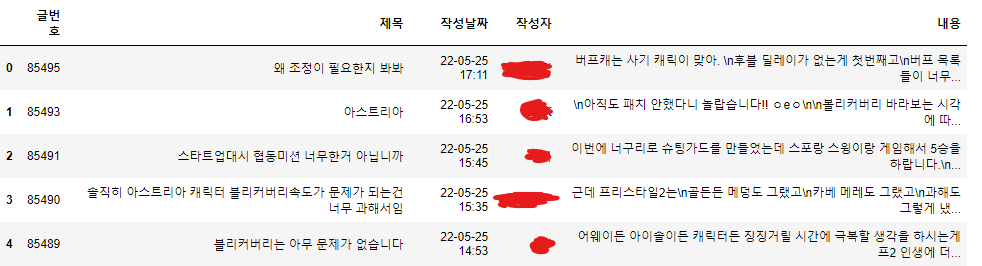
Pandas의 head 메서드를 사용하여 상위 5개의 행만 확인한다.
8. 데이터 프레임 -> csv 파일로 저장
df.to_csv('FreeStyle2_board.csv', encoding='utf-8-sig')데이터란 보유해야 가치가 있는 법이므로 파일을 만들어 저장해준다!
크롤링 시 발생했던 문제점
1. 게시글의 url이 javascript 함수로 숨겨져 있다.
사실 원래 크롤링 계획은 게시글마다의 url을 별도 추출한 후,
게시글을 크롤링할 계획이었으나...

위처럼 URL이 숨겨져 있었다...
본문에서는 url을 추출하는 방법을 몰라서
울며 겨자 먹기로 게시글을 하나하나 접속하여 크롤링했으나
KDT 교육을 함께 수강하는 수강생분께서 url을 추출할 수 있는 함수를 만들어 주셨다~!
def freestyle2_url_parser(elem):
"""정확한 a 테그가 들어온다는 가정."""
js = elem.get_attribute("onclick")
idx = js.replace("javascript:fnView('./view.do', ", "").replace(")", "")
return f"https://fs2.joycity.com/web/community/board/view.do?seq={idx}"
browser = get_browser(headless=False)
a_tag = browser.find_element_by_css_selector(".tb-type01 > tbody:nth-child(4) > tr:nth-child(4) > td:nth-child(3) > a:nth-child(1)")
freestyle2_url_parser(a_tag)
사실 답은 간단했다.
a 태그의 onclick arrtibute의 저 끝의 번호가 바로 게시글의 번호를 나타낸 것...
즉, 번호를 추출한 후 게시글 url의 규칙에 맞게 삽입하면 끝~...
해결법을 제공해주신 수강생님 감사합니다!
'Data Processing > Crawling Practice' 카테고리의 다른 글
| [Crawling Practice] 3. 인스타그램 크롤링 (0) | 2022.05.26 |
|---|---|
| [Crawling Practice] 1. 메이플스토리 인벤/자유게시판의 데이터 수집 (0) | 2022.05.24 |
| [Crawling Practice] 0. 프롤로그 (0) | 2022.05.24 |

