
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- object detection
- TensorFlow Object Detection Model Build
- Towards Deep Learning Models Resistant to Adversarial Attacks
- TensorFlow Object Detection API install
- VOC 변환
- 개발흐름
- Docker
- AI Security
- 커스텀 애니메이션 적용
- 크롤링
- TensorFlow Object Detection Error
- 논문 분석
- Paper Analysis
- Object Detection Dataset 생성
- 논문분석
- Git
- Carla
- 리눅스 빌드
- DACON
- Linux build
- Branch 활용 개발
- InstructPix2Pix
- Custom Animation
- paper review
- CARLA simulator
- 기능과 역할
- TensorFlow Object Detection 사용예시
- 사회초년생 추천독서
- 객체 탐지
- DOTA dataset
- Today
- Total
JSP's Deep learning
[Paper Review - Diffusion] InstructPix2Pix : Learning to Follow Image Editing Instruction 본문
[Paper Review - Diffusion] InstructPix2Pix : Learning to Follow Image Editing Instruction
_JSP_ 2023. 4. 4. 23:171. InstructPix2Pix란?
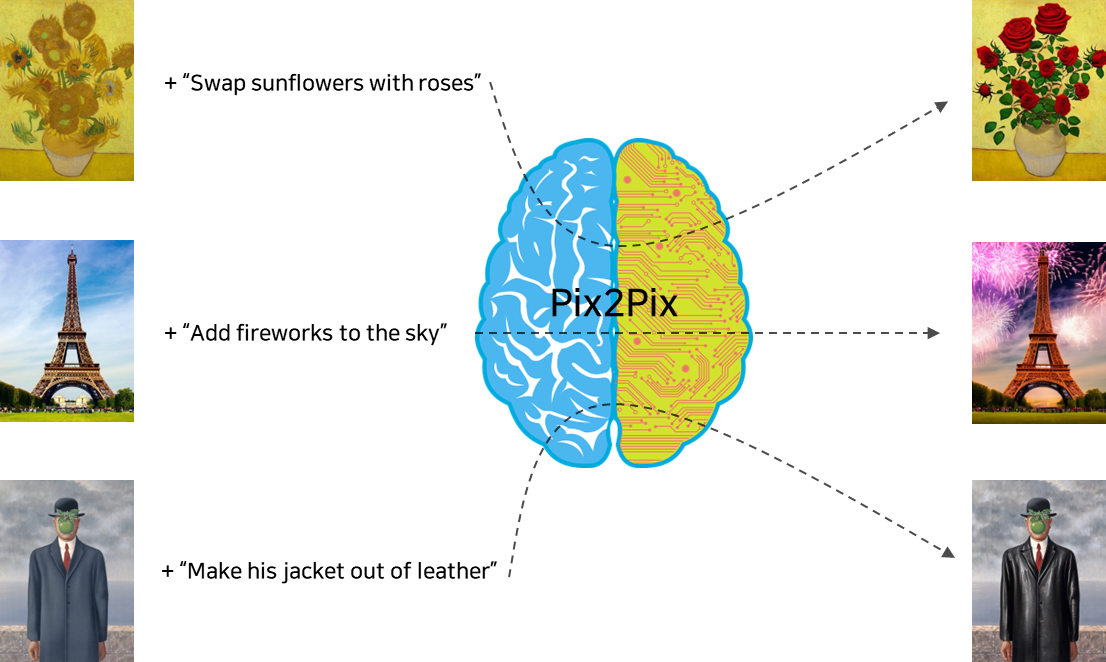
- 이미지와 텍스트(지시어)의 입력으로 이미지를 지시어대로 편집하는 Diffusion 모델
- Prompt to Prompt 기법을 적용하여 편집된 이미지와 편집 전 이미지의 일관성을 보장
- GPT-3와 Stable Diffusion모델을 사용하여 이미지와 그에 맞는 지시어 그리고 편집된 이미지의 학습데이터를 구축
(즉, 기존의 대형 언어모델과 이미지 생성 모델을 사용하여 학습데이터셋 구축) - 기존 image to image 모델과 다르게 이미지 스타일 변화, 배경 변경 등 다양한 이미지 편집 기능을 수행
(하지만 학습데이터셋에 존재하지 않는 편집기능은 수행할 수 없음)
2. 용어정리
2.1. Prompt to Prompt
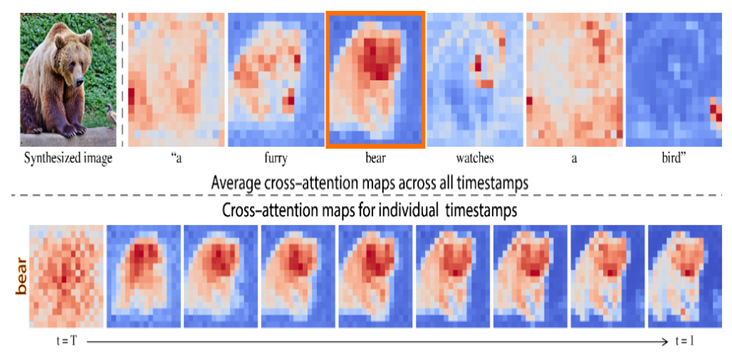
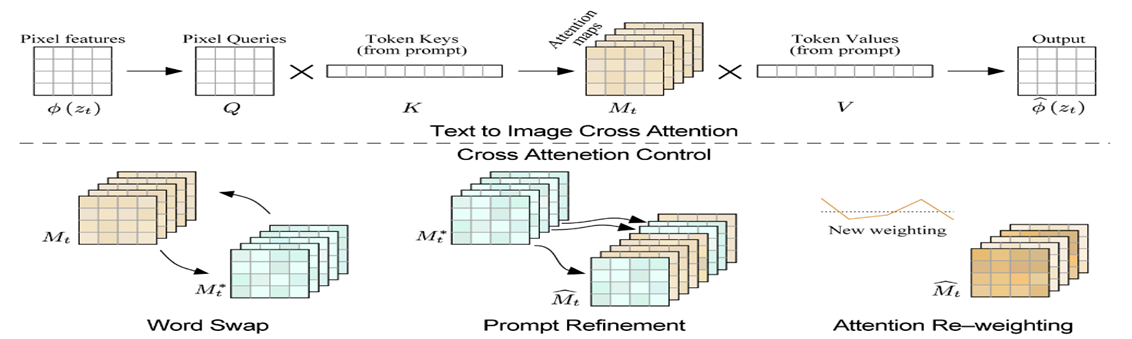
- Prompt의 각 토큰(단어)이 어떤 픽셀과 유사한지를 텍스트와 이미지 간의 연산을 통해서 Cross Attention 맵을 구성 한다. 그리고 이 맵을 Diffusion(이미지 편집 Task) 중 반영하여 원본 이미지와 편집된 이미지의 일관성을 유지한다.
(InstructPix2Pix의 근간이 되는 기법이므로 해당 논문을 직접 분석해 보는 것을 추천)
3. 학습데이터셋 구축
3.1. 전체 과정
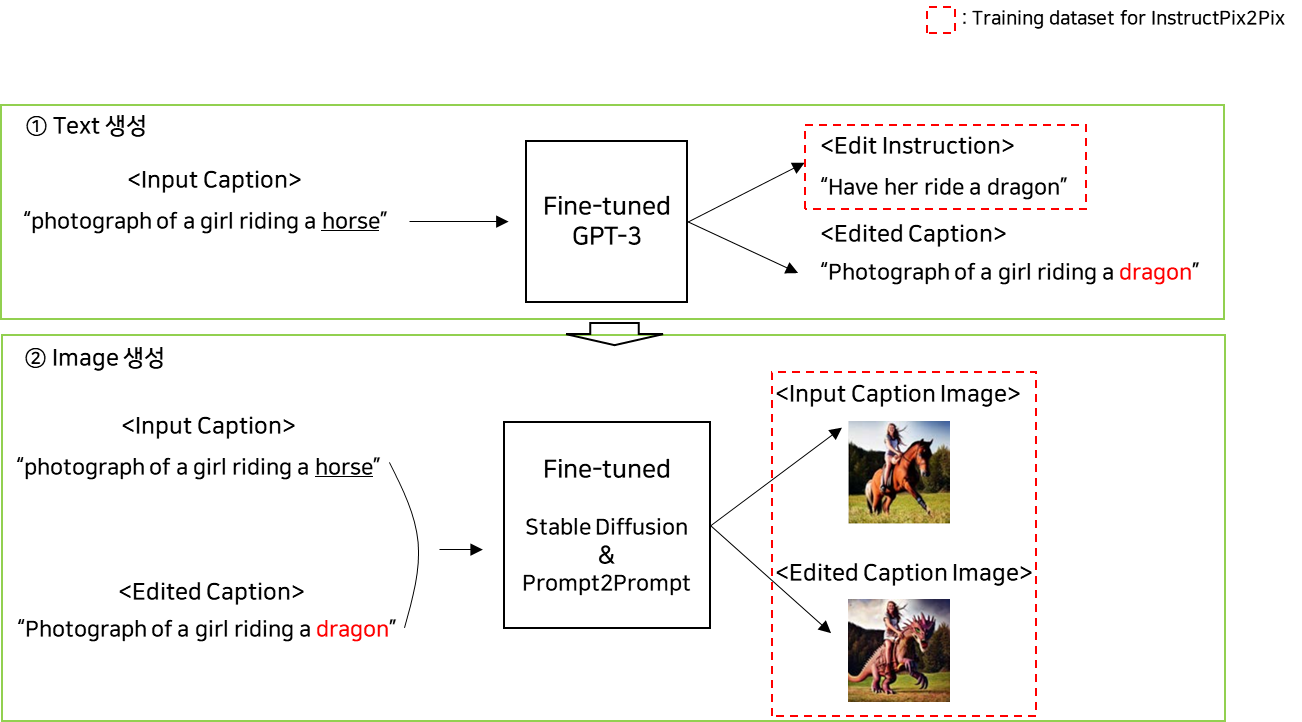
- 텍스트(지시어) : GPT-3가 이미지에 대한 캡션을 입력으로 받으면 지시어와 그에 따라 수정된 캡션을 생성하도록 파인튜닝
- 이미지(편집 전 이미지와 편집 후 이미지) : 앞서 생성한 (일반 캡션, 편집된 캡션)을 파인튜닝된(Prompt to Prompt 기법 적용하여 이미지 일관성 보장) Stable Diffusion + Prompt to Prompt 모델에 입력하여 편집전 이미지와 편집후 이미지를 생성한다.
3.2. GPT-3 파인튜닝

- 캡션 문장만 존재하는 LAION 데이터 셋에 대해서 캡션 문장에 대한 편집 지시어와 그에 따른 결과인 편집된 캡션을 수기로 생성
- 생성된 700여 개의 (캡션, 편집 지시어, 편집된 캡션)의 데이터 셋을 사용하여 GPT-3을 파인튜닝
(-> 캡션에 대해서 편집 지시어와 편집된 캡션을 생성하도록 파인튜닝) - 파인튜닝된 GPT-3에 사용하지 않았던 LAION 데이터 셋의 캡션을 입력으로 사용하여 약 450,000개의 (캡션, 편집 지시어, 편집된 캡션) 데이터를 생성
3.3. Stable Diffusion 파인튜닝
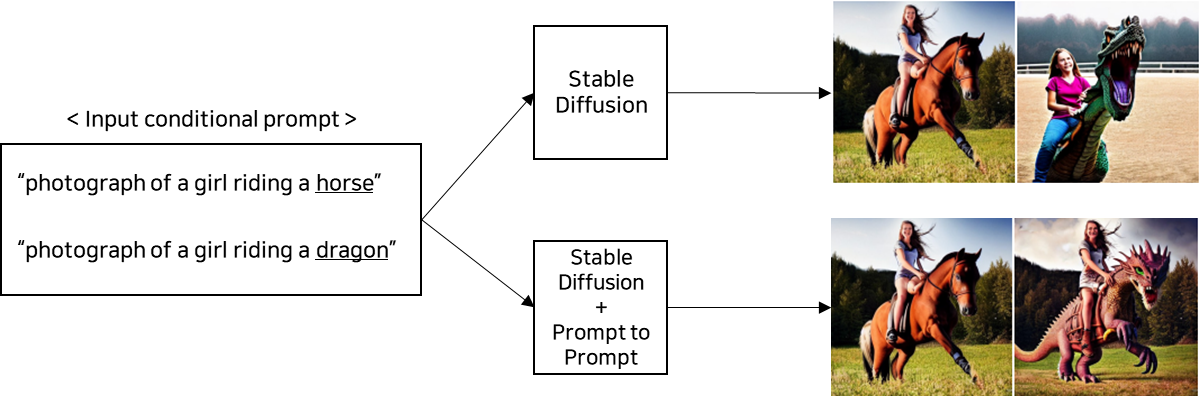
- 위의 그림은 일반 Stable Diffusion을 사용했을 때와 Prompt to Prompt 기법을 적용하였을 때의 차이점을 나타낸 그림이다. 즉, Prompt to Prompt을 사용하면 크게 다르지 않은 두 캡션에 대해서 약간의 편집만 반영되고 일관성이 보장되는 이미지를 생성한다.
4. InstructPix2Pix 적용 기법
- 기본 베이스는 Stable Diffusion + Prompt to Prompt이다.
- Stable Diffusio + Prompt to Prompt에서 편집 전 이미지 - 편집 후 이미지의 유사도를 조정하기 위해서 Denoising하는 과정 중 반영되는 Attention weights의 비율을 조절한다. => 다양한 이미지 편집을 위해 너무 유사하면 안 되기 때문.
(해당 비율에 대해서 측정하기 위해서 텍스트와 이미지 간의 유사도를 비교할 수 있는 CLIP metric을 사용)
4.1. 수식설명
Denoising에 대한 수식
(지시어를 이미지 편집에 반영)


- 수식을 살펴보면, 지시어와 이미지를 모두 반영하여 Noise의 예측에 대한 오차가 최소가 되도록 학습을 한다.
=> 즉, 이 과정을 통해서 이미지가 지시어에 따라 편집되도록 학습한다.
Classifier-free Guidance 수식
(편집되는 이미지의 유사도 조절 -> 다양성 조절)

- 즉, 이미지와 텍스트에 대한 Denoising 반영 비율을 각각 조절할 수 있다.
=> 다양한 편집기능을 수행할 수 있다.
Classifier-free Guidance 수식 도출

4.2. 수식 적용 예시

5. InstructPix2Pix 학습
5.1. 학습정보
-
Base Model : Stable Diffusion
-
Initialization : Stable Diffusion v1.5 check point
-
Other training setting : public Stable Diffusion code
-
Input resolution : 256 x 256
-
Denoising step : 100 steps
-
Epochs : 10000
-
Batch size : 1024
-
8 x 40GB NVIDIA A100 GPU – 25.5 hours
-
Learning rate : 0.0001 (warm up 없이 진행)
-
Inference time => 9 seconds with A100 GPU
5.2. 전체 과정
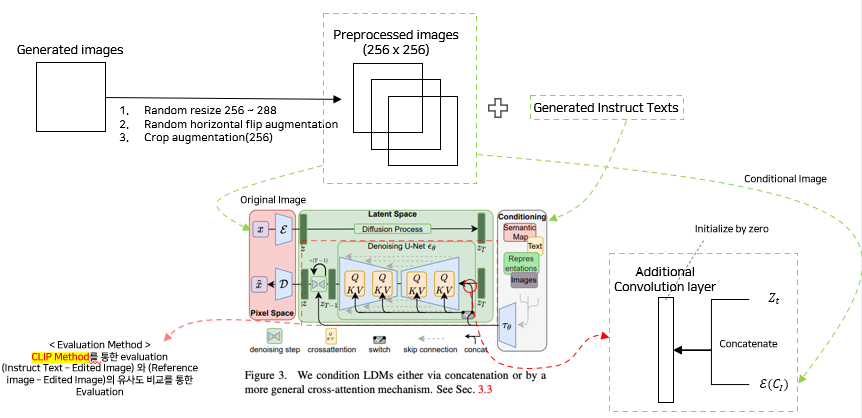
6. 실험
6.1. 이미지 생성 결과 비교

- InstructPix2Pix는 편집후 이미지의 일관성과 품질 모두 우수(시각적 판단)
6.2. 이미지 생성 시 성능 그래프
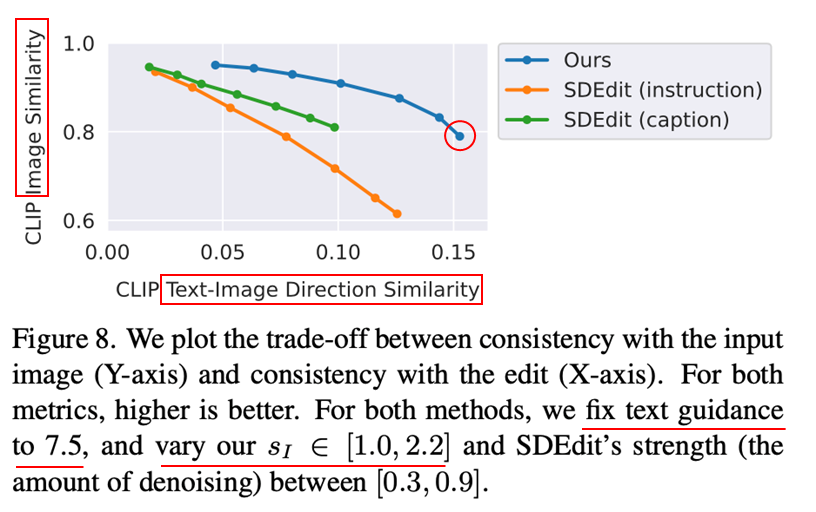
- InstructPix2Pix는 편집된 이미지에 대한 지시어 반영 정도와 원본 이미지와의 유사도 모두 우수하다.
7. 한계점

- 학습데이터 구축 시 대형 이미지 생성 모델 및 텍스트 생성 모델을 사용했기 때문에 이에 의존하는 경향이 있다.
- 학습데이터에 존재하지 않는 이미지 편집 기능에 대해서는 수행할 수 없다.
< 참고 >
[1] Time Brooks, Aleksander Holyski, Alexei A. Efros. InstructionPix2Pix: Learning to Follow Image Editing Instructions, IN CVPR, 2022.
[2] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon. SDEdit: Guided Image Sysnthesis and Editing with Stochastic Differential Equations, IN CVPR, 2021.
[3] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, Daniel Cohen-Or. Prompt-to-Prompt Image Editing with Cross-Attention Control, IN CVPR, 2022.
[4] Omer Bar-Tal1∗ , Dolev Ofri-Amar1∗ , Rafail Fridman1∗ , Yoni Kasten2 , and Tali Dekel1. Text2LIVE: Text-Driven Layered Image and Video Editing, IN ECCV, 2022.
[5] Donghua Wang, Timsong Jiang, Jialiang Sun, Weien Zhou, Xiaoya Zhang, Zhiqiang Gong, Wen Yao, Xiaoqian Chen. FCA : Learning a 3D Full-coverage Vehicle Camouflage for Multi-view Physical Adversarial Attack , IN CVPR, 2021.
[6] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Bjorn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models, IN CVPR, 2022.
[7] https://openai.com/blog/clip/
CLIP: Connecting text and images
We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision. CLIP can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized,
openai.com
[8] https://github.com/timothybrooks/instruct-pix2pix