
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Git
- TensorFlow Object Detection 사용예시
- 사회초년생 추천독서
- TensorFlow Object Detection API install
- Branch 활용 개발
- InstructPix2Pix
- 크롤링
- 커스텀 애니메이션 적용
- 개발흐름
- Paper Analysis
- DOTA dataset
- 논문 분석
- 논문분석
- Docker
- 리눅스 빌드
- CARLA simulator
- Carla
- 객체 탐지
- Towards Deep Learning Models Resistant to Adversarial Attacks
- Linux build
- VOC 변환
- Object Detection Dataset 생성
- TensorFlow Object Detection Model Build
- paper review
- DACON
- object detection
- 기능과 역할
- Custom Animation
- AI Security
- TensorFlow Object Detection Error
- Today
- Total
JSP's Deep learning
[Paper Review - Object Detection] 5. YOLO9000 : Better, Faster, Stronger 본문
[Paper Review - Object Detection] 5. YOLO9000 : Better, Faster, Stronger
_JSP_ 2023. 2. 13. 22:571. 요약
-
YOLO9000은 9000개 이상의 categories에 대해서 detection이 가능한 object detection system이다. (YOLOv1은 200-classes)
-
YOLOv2는 Speed와 accuracy의 tradeoff가 잘 절충된 model이다.
-
YOLO9000에서는 Classification dataset과 detection dataset을 결합하여 학습하는 방법을 사용했다.
-
결론적으로, COCO dataset에 없는 class에 대해서도 Object detection이 가능하게 되었다.
(단, 비슷한 형태의 세부 카테고리의 객체에 대해서 탐지가 가능해진 것!)
2. 주요 용어(간단 정리)
...상세한 사항은 관련 논문을 찾아봐야합니다...
1) ResNet

-
Residual neural Network의 줄임말, vanishing gradient 문제를 해결하기 위해 만들어진 네트워크이다.
-
중간 layer을 거친 Input value와 identity mapping 과정을 거친 Input value의 합을 출력한다.
-
입력과 출력의 차원이 다를 경우에는 y=F(x, Wi)+Ws ∗x로 구할 수 있다.
-
Wi : CNN layers의 가중치
- Ws : identity mapping을 덧셈 가능하게 해주는 값
-
2) SSD

- Single Show multibox Detector의 줄임말, One-Stage detector로 YOLO의 검출 성능을 높이고, 속도는 유지한 모델.
- Faster R-CNN보다 더 좋은 검출 성능을 가졌다.
- Default Box를 통해서 객체 검출을 수행한다.
3) Hierarchical view of object classification

-
대, 중, 소 등 분류를 하기위해서 카테고리를 계층적으로 나누어 연결시킨 트리 혹은 맵
- YOLO9000은 다음의 구조를 이용하여 탐지가 가능한 Class를 대폭 늘릴 수 있었다.
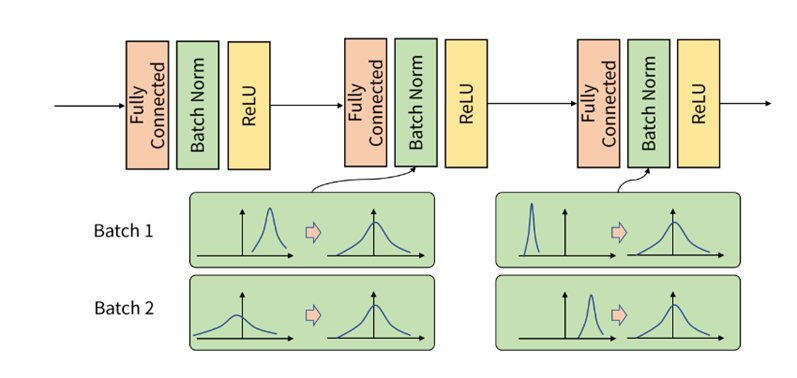
4) Batch normalization
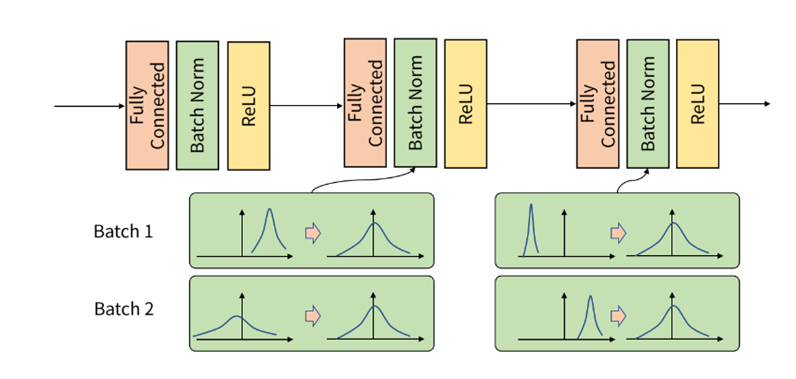
-
각 배치 단위 별로 평균과 분산을 이용해 정규화 하는 것, 즉 데이터 분포를 비슷하게 조정하는 것
5) Fine-grained

-
좀 더 세분화 시킨다는 의미로, Classification에서 Fine-grained은 Labeling을 더 세세하게 한다는 의미이다.
-
Ex. 개, 고양이, 사람 => 골든 리트리버, 러시안 블루, 백인
6) WordNet (Direct graph 구조)
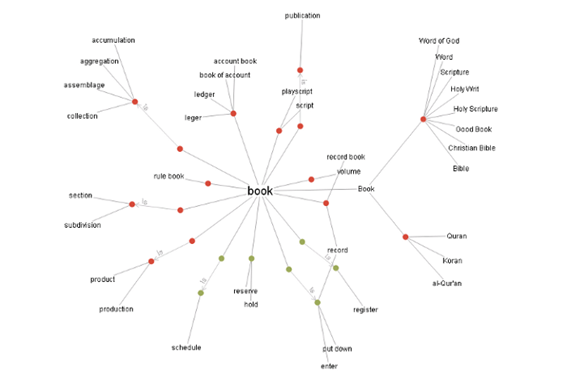
- 영어의 의미 어휘 목록으로, 영어 단어를 ‘synset’이라는 유의어 집단으로 분류하여 일반적인 정의를 제공하고, 이러한 어휘목록 사이의 다양한 의미 관계를 기록한다.
- WordNet의 117,000개의 synsets 각각은 소수의 “개념적 관계”를 통해 다른 synsets와 연결되어 있는 구조를 가진다.
7) Global Average Pooling
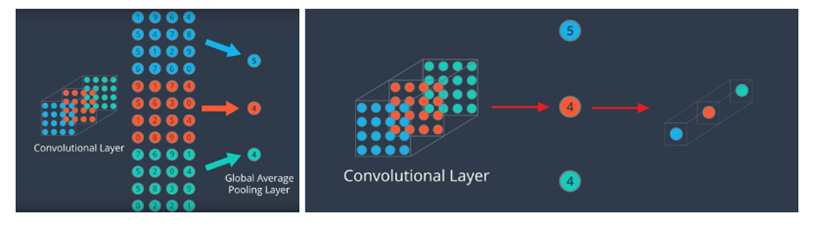
-
feature를 1차원 Vector로 만들기위한 기법 (FCs 대체)
-
같은 Channel의 features을 평균하여 Channel의 개수만큼의 원소를 가지는 vector로 만든다.
-
Ex. 7 x 7 x 512 => 512
8) Top – 1 accuracy vs. top – 5 accuracy
- Top – 1 accuracy
- softmax의 output에서 가장 높은 값을 가지는 class가 정답일 경우에 대한 지표
- (가장 높은 값을 가지는 class가 정답인 경우의 수)/(예측 횟수)
- Top – 5 accuracy
- softmax의 output에서 상위 5개의 값을 가지는 classes 중 정답이 있을 경우에 대한 지표
- (상위 5개의 값을 가지는 classes 중 정답이 있는 경우의 수)/(예측 횟수)
- 예시)

- GT(정답) class가 비행기인 경우
- Top – 1 acc = 1
- Top – 5 acc = 1
- GT(정답) class가 말인 경우
- Top - 1 acc = 0
- Top – 5 acc = 1
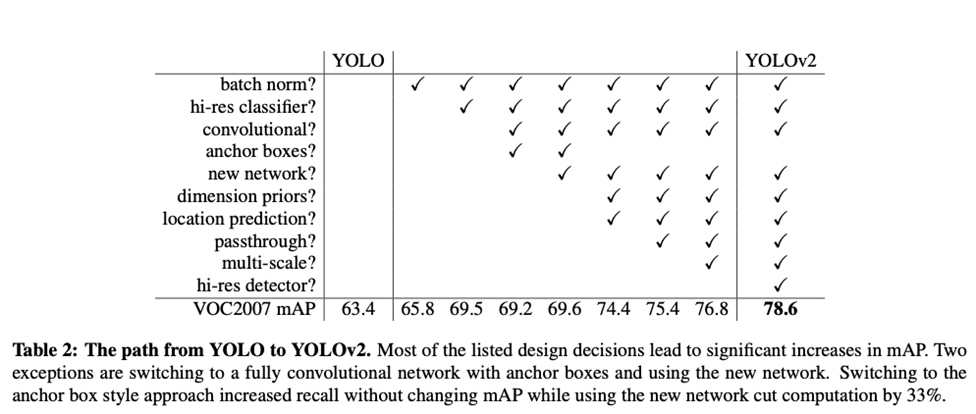
2. YOLOv2 & YOLO9000
1) Better
-
YOLOv1에 대해 여러 기법들을 적용
=> YOLOv1의 localization error 문제 개선(mAP 개선)
A. Batch Normalization
- YOLO에 있는 모든 Convolution layers에 batch normalization을 추가 => mAP 2% 향상
- 다른 형태의 정규화에 대한 필요성 제거, 수렴에 큰 개선
- 모델의 regularize 영향 : Dropout 제거 -> Overfitting(x)
B. High Resolution Classifier
- Classification Network를 ImageNet dataset으로 10 epochs동안 full 448 x 448 image로 fine tuning
- Detection을 수행하는 Resulting network을 fine tuning

∴ High resolution classification network => 4% mAP 향상
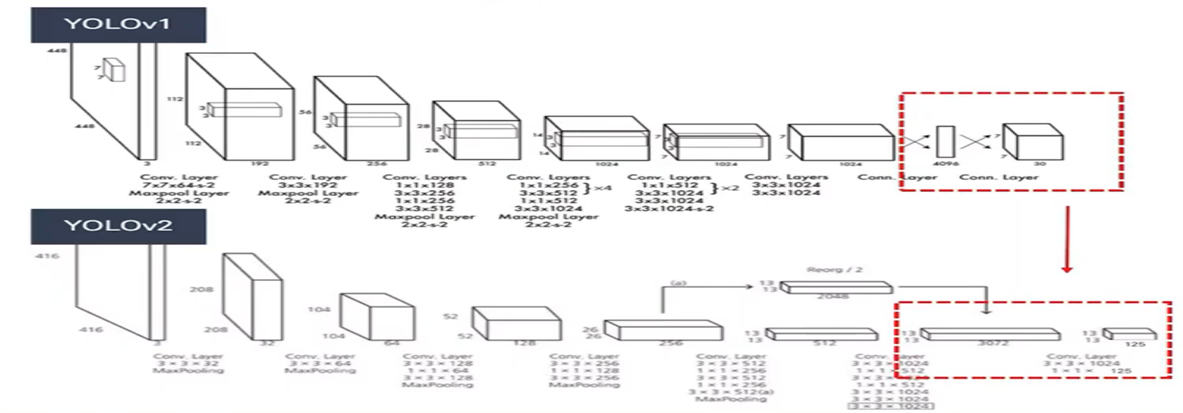
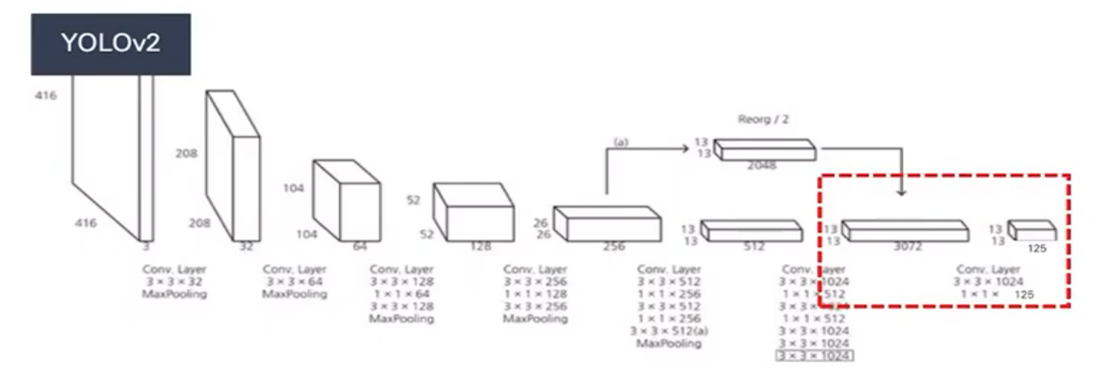
C. Convolution with anchor boxes
- Coordinates을 직접 예측하는 것 대신 offsets을 예측 -> 단순화
- YOLOv1의 Fully connected layers을 제거 -> global avg layer
- Anchor boxes을 사용하여 bounding box 예측
- 구조
- 416 x 416의 input size -> 13 x 13 feature map
- 큰 Object의 경우 중앙에 위치하는 경향 ↑
- Feature map 짝수이면, 4개의 cell로 중심 예측 -> 부정확
- Feature map 홀수이면, 1개의 cell로 중심 예측 -> 정확
- 각 grid-cell마다 모든 anchor boxes로 Class probability와 Objectness 예측
- 총 예측하는 box의 수 = 13 x 13 x k (anchor boxes 수)
- Grid cell에서의 anchor box 동작 예시 (k = 5, C = 20)

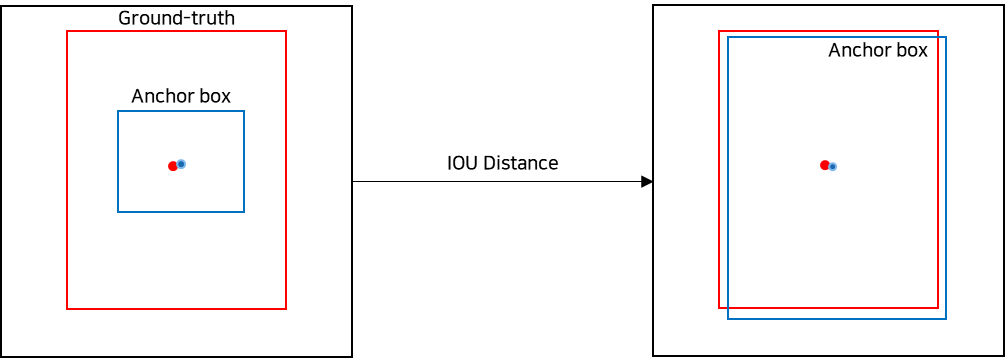
D. Dimension Clusters
- Anchor boxes의 scales와 aspect ratio에 대해서 k-means을 통해서 결정
- 단, distance는 다음과 같이 정의
- d(box, centroid)=1 -IoU(box, centroid)
- Euclidean Distance를 사용하면 다음과 같은 문제 발생
-
실험을 통한 적절한 Cluster의 개수 즉, anchor boxes의 개수 선정
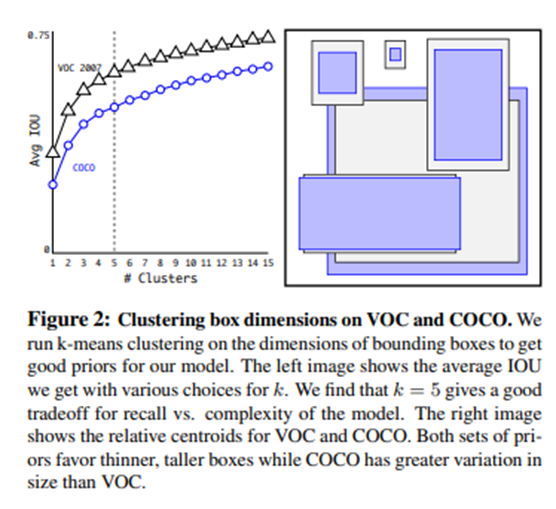
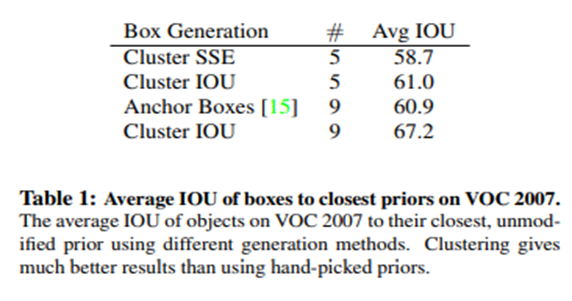
- Cluster ↑ Complexity ↑Avg IOU ↑
- k = 5일 때, Avg IOU와 complexity 조화
- 기존 방식에 비해 Avg IOU ↑
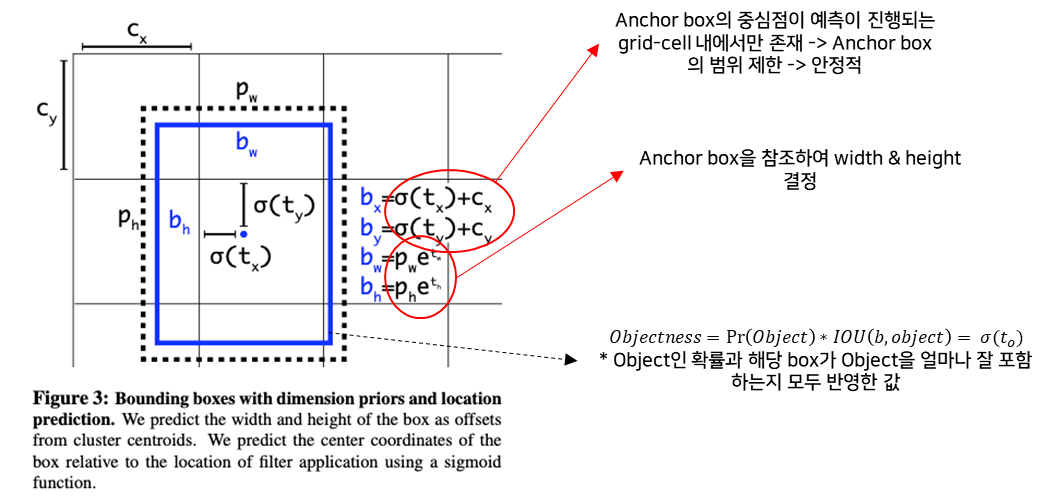
E. Direct location prediction
-
기존 Faster R-CNN에서 Bounding box coordinates 예측 식
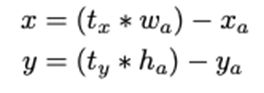
- 단점, t_x에 대한 제한이 없기 때문에 predicted box와 관계없이 Anchor box가 이미지 어디든 위치-> 초기 학습 불안
-
YOLOv2의 Bounding box coordinates 예측 식
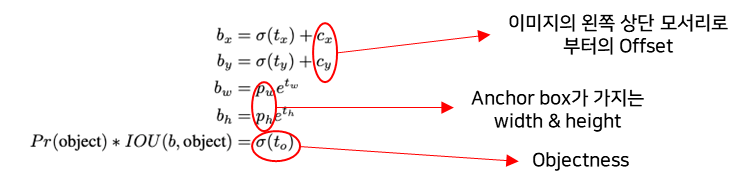
- (t_x, t_y, t_w, t_h) : 예측된 bounding box의 indirectly 값
- 예측 범위를 제한 -> 안정적인 네트워크
- 수식 분석
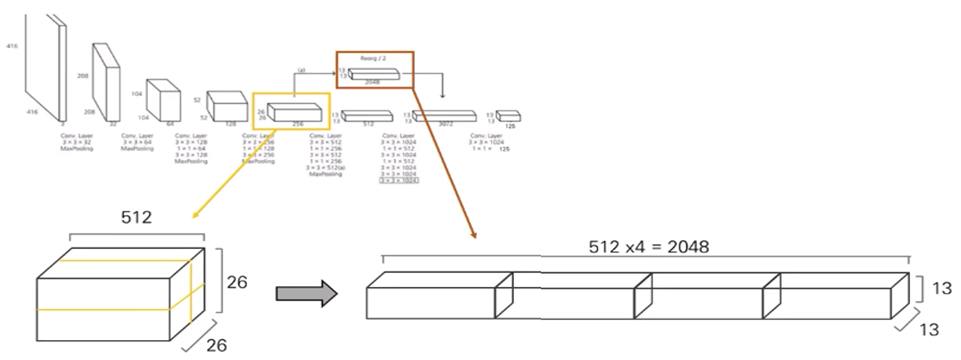
F. Fine-Grained Feature
- 고해상도의 feature map -> 작은 물체 탐지 용이
- 저해상도의 feature map -> 큰 물체 탐지 용이
=> passthrough layer -> Concatenate => 작은 + 큰 물체 탐지 용이
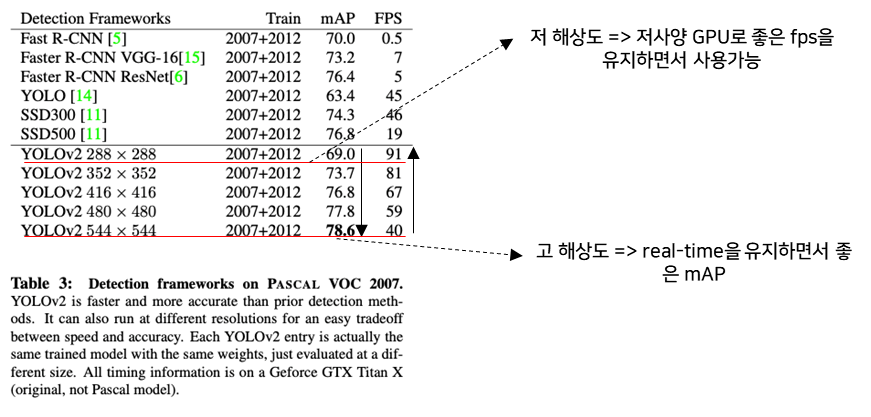
G. Multi-Scale Training
- 10 batches 마다 여러 사이즈의 이미지 중 랜덤하게 선택 (단, Network가 32의 배율로 down-sampling을 진행하기 때문에 이미지의 사이즈는 32의 배수) -> {320^2, 352^2, …, 608^2}
- 이미지의 Scales에 둔감
- 해상도와 mAP, FPS의 tradeoff
2) Faster
- YOLOv1보다 더 빠르고 정확한 탐지를 위해 개선 -> CLS Net 교체
- CLS Net 연산 & 정확도 (224 x 224 기준)
- VGG-16
- operations : 30.69 billion
- accuracy(top – 5) : 90%
- GoogleNet(in YOLOv1)
- operations : 8.52 billion
- accuracy(top – 5) : 88%
- DarkNet(in YOLOv2)
- operations : 5.58 billion
- accuracy(top – 5) : 91.2%
A. Darknet-19
- 구조
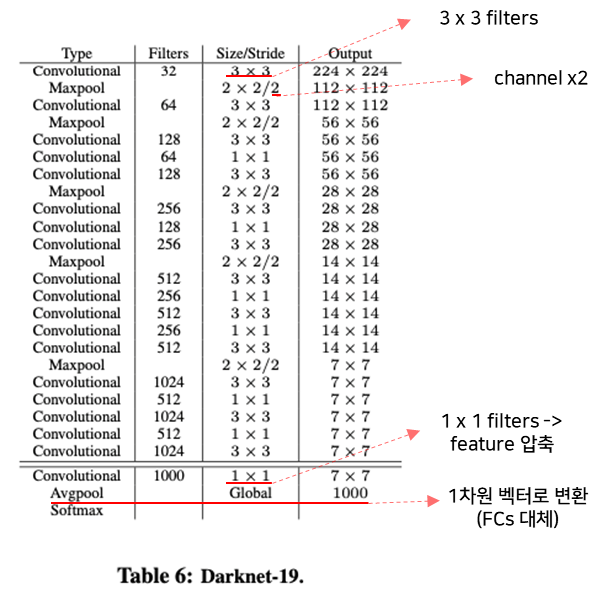
B. Training for classification

- epochs
- pre-trained : 160 epochs
- fine-tuning : 10 epochs
- SGD optimizer
- starting learning rate : 0.1 (fine-tuning에서는 0.001)
- Polynomial rate decay : 4^2
- weight decay : 0.0005
- momentum : 0.9
- Library : Darknet neural network framework
- data augmentation
- Random crops, rotation, hue, saturation, exposure shifts
- Input size
- Pre-trained : 224 x 224
- fine-tuning : 448 x 448
- Performance
- top-1 acc : 76.5%
- top-5 acc : 93.3%
C. Training for detection
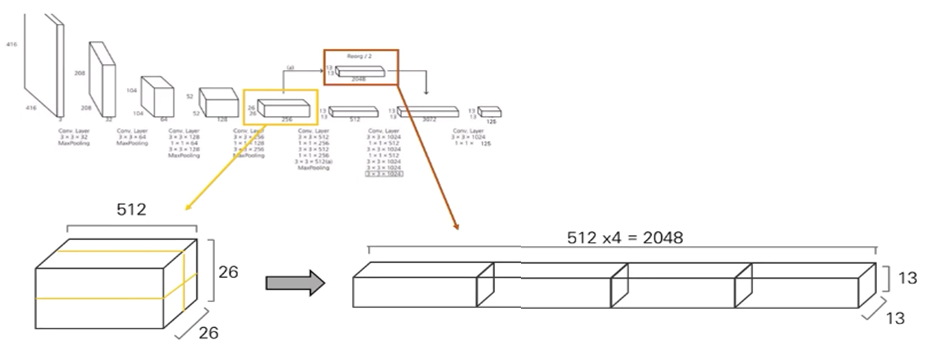
- epochs : 160 (10 – 60 – 90)
- SGD optimizer
- starting learning rate : 0.001
- weight decay : 0.0005
- momentum : 0.9
- data augmentation : cls training과 동일
-
passthrough layer -> 작은 물체에 대한 탐지 ↑
3) Stronger
- YOLO9000
- YOLOv1에서 Categories의 다양성이 부족한 문제
- Classification dataset + Detection dataset => Class ↑
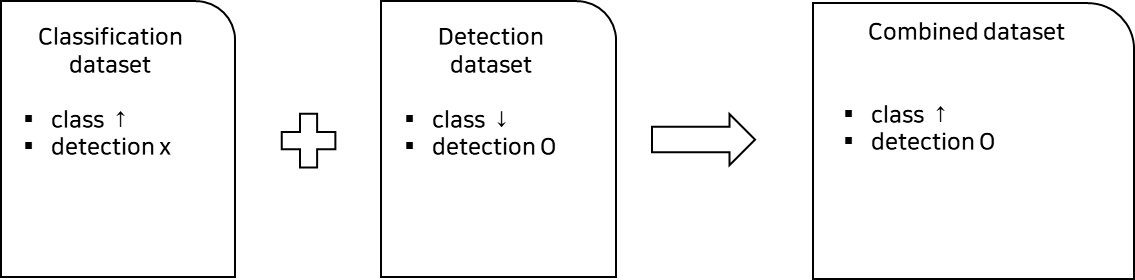
A. Hierarchical classification
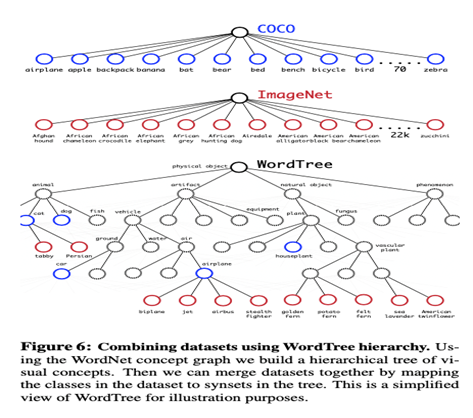
- WordNet을 이용하여 WordTree 구성
- 구성방법
- WordNet에서 physical object에 대해서만 진행
- 하나의 pass만 존재하는 경우, 곧바로 추가
- 그 외의 경우 반복적으로 조사하여, tree의 크기가 작아지는 방향으로 경로를 선택하여 추가(한 가지 개념에 대해 2가지 경로가 존재한다면 더 짧은 경로를 선택)
- 이후 COCO dataset & ImageNet dataset을 WordTree를 참고하여 매핑
-
WordTree을 이용한 classification
-
예시) Yorkshire terrier에 대해 classification

- Pr(Yorkshire Terrier)=Pr(Yorkshire Terrier|Terrier) ∗Pr(Terrier│dog)∗Pr(dog│animal)∗Pr(animal│physical)
- Classification에서는 Pr(physical) = 1이라고 가정한다.
- Pr(physical object)은 YOLOv2의 objectness predictor로 예측한다.
B. Dataset combination with WordTree
- WordTree에 대하여 Dataset 매핑
- WordTree을 dataset과 mapping하는 경우, dataset에 존재하는 node로 가기 위해 필요한 중간 path는 모두 추가한다.
- COCO dataset과 ImageNet dataset -> WordTree mapping
C. Joint classification and detection
- Joint train
- dataset : Combined dataset (COCO + 9000-classes ImageNet dataset)
- COCO oversampling -> COCO : ImageNet = 1 : 4
- dataset : Combined dataset (COCO + 9000-classes ImageNet dataset)
- priors : 3 (모델 사이즈가 너무 커져서 3개의 box priors만 사용)
- Back-propagation
- Classification
- Classification image에 대해서는 classification loss만 학습.
- 예측 Label의 Level과 그 아래 Level에 대해서만 학습이 진행된다.
- Detection
- 일반 back-propagation 진행 (cls and bbox reg loss)
- Classification
- Ex. Dog라고 predict 된 data를 학습하는 경우
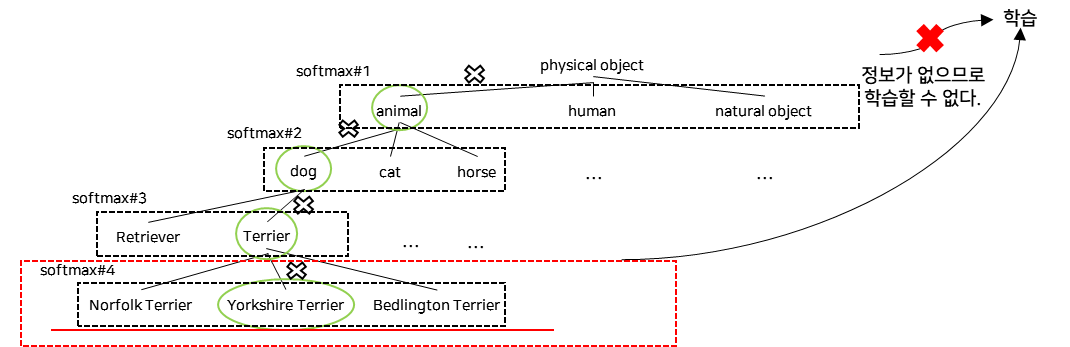
- Objectness loss
- Ground-truth box와 predicted box의 IoU >= 0.3일 때만, Objectness loss을 계산한다.
- 결론
- YOLO9000은 ImageNet dataset에서 분류에 대한 학습, COCO dataset에서 detection에 대한 학습을 한다.
- COCO dataset의 44 class에 대해서만 ImageNet dataset과 joint train을 진행했더니, COCO dataset의 나머지 156 class에 대해서 본적이 없음에도 16.0 mAP의 값을 얻었다.
- 새로운 동물의 종류에 대해서는 학습하지만, 옷과 선글라스 같은 object에 대해서는 잘 학습하지 못했다. => COCO dataset이 동물에 대해서만 잘 일반화 되어있기 때문

3. Summary
1) 수식
YOLOv1과 YOLOv2의 수식 비교
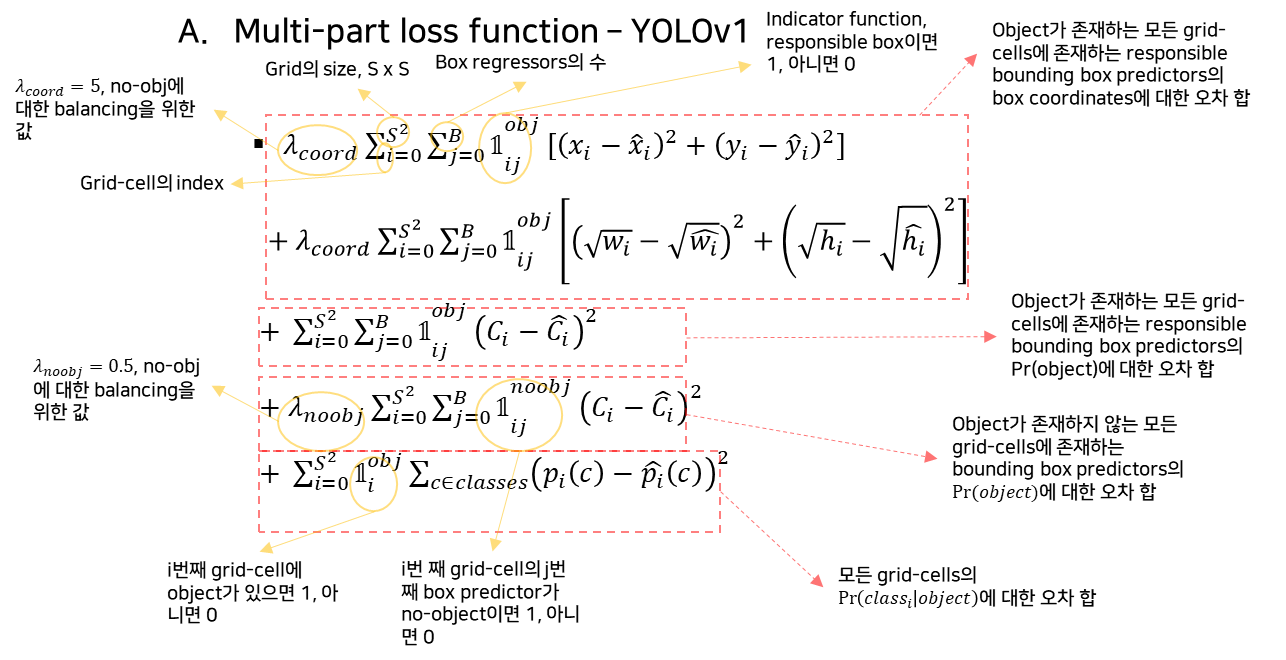
A. Multi-part loss function – YOLOv1
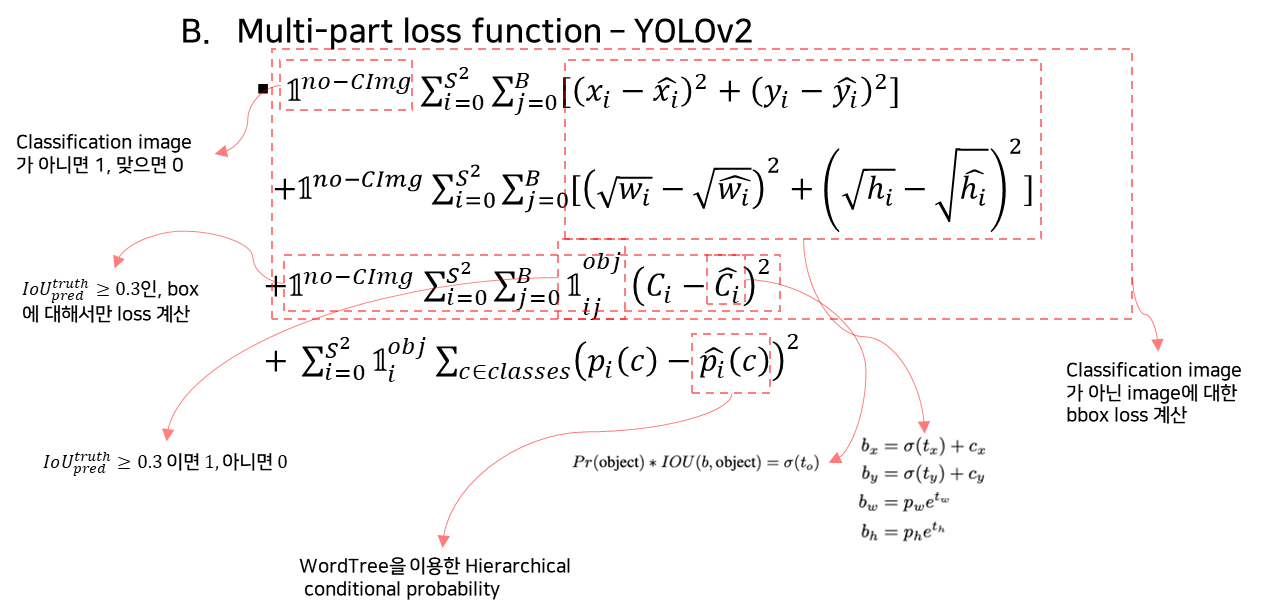
B. Multi-part loss function – YOLOv2
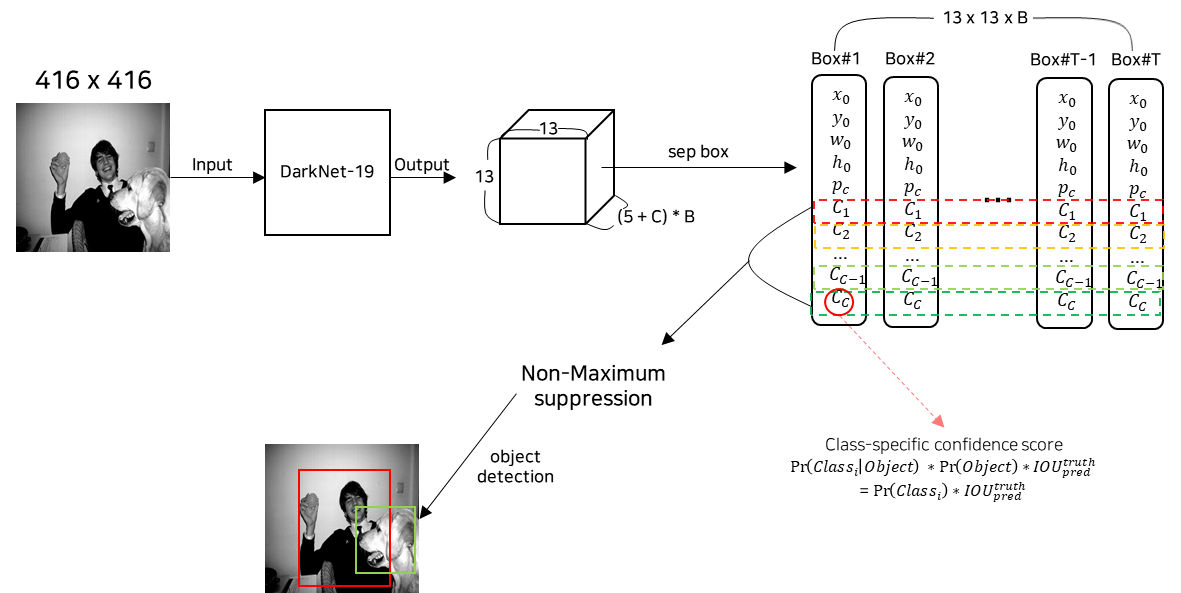
2) 추론
< Reference >
'Paper Review > Object Detection' 카테고리의 다른 글
| [Paper Review - Object Detection] 6. YOLOv3 : An Incremental Improvement (0) | 2023.02.26 |
|---|---|
| [Paper Review - Object Detection] 4. YOLOv1 (0) | 2023.01.25 |
| [Paper Review - Object Detection] 3. Faster R-CNN (0) | 2023.01.21 |
| [Paper Review - Object Detection] 2. Fast R-CNN (0) | 2023.01.15 |
| [Paper Review - Object Detection] 1. R-CNN (0) | 2023.01.10 |



