
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- TensorFlow Object Detection Model Build
- InstructPix2Pix
- Custom Animation
- TensorFlow Object Detection API install
- Carla
- VOC 변환
- 사회초년생 추천독서
- 기능과 역할
- Git
- Docker
- TensorFlow Object Detection 사용예시
- 객체 탐지
- 크롤링
- 논문분석
- 개발흐름
- Towards Deep Learning Models Resistant to Adversarial Attacks
- TensorFlow Object Detection Error
- 논문 분석
- paper review
- 리눅스 빌드
- 커스텀 애니메이션 적용
- Object Detection Dataset 생성
- CARLA simulator
- object detection
- AI Security
- DOTA dataset
- Branch 활용 개발
- DACON
- Paper Analysis
- Linux build
- Today
- Total
JSP's Deep learning
[Paper Review - Object Detection] 6. YOLOv3 : An Incremental Improvement 본문
[Paper Review - Object Detection] 6. YOLOv3 : An Incremental Improvement
_JSP_ 2023. 2. 26. 00:501. 요약
- YOLOv3는 Residual 기법이 적용된 DarkNet-53 구조를 사용하였다.
- 클래스 분류에 Logistic classifiers를 사용하였다.
- K-means 클러스터링을 통해서 Bounding box priors을 구성했다.
(Bounding box priors에 대해서는 뒤에서 설명한다) - 3-scales feature map을 사용하여 feature을 추출한다.
- YOLOv3는 YOLOv2와 비교했을 때, 작은 객체에 대한 탐지 성능이 향상되었다.
2. 용어정리
1) Linear activation

- f(x) = cx의 식을 가지는 선형 활성화 함수
- 다중 출력이 가능하다.
- 미분 값이 상수이기 때문에 오차역전파를 통한 학습이 불가능하다는 특징이 존재한다.
2) Upsampling
- Deconvolution 과정으로, CNN을 거쳤던 feature을 거치기 전 상태로 되돌리는 연산을 수행한다.
- pooling layer를 복원하는 방법
- Nearest Neighbor Unpooling : 복원을 진행할 때, 값을 단순히 복제한다.
- Bed of Nails Unpooling : 복원을 진행할 때, 정해진 위치에만 값을 저장하고 나머지는 0으로 만든다.
- Max Unpooling : 복원을 진행할 때, Max pooling된 위치를 기억하여 그 위치에 값을 복원하고 나머지는 0으로 만든다.

- 행렬연산을 통해 복원하는 방법(Transpose Convolution)
- 예시) padding = 0, stride = 1, kernel = 3 x 3 일 때의 복원

3) Feature pyramid networks

- Convolution network에서 지정한 layer 별로 feature map을 추출하여 사용하는 network로 여러 해상도를 가지는 feature map을 사용하여 추론을 진행한다.
4) Focal loss

- One-stage 객체 탐지 모델 학습 시, Class 불균형 문제를 해결하기 위한 손실함수 (Back-ground ↑vs. object↓)
- One-stage 객체 탐지 모델에서 각각이 학습에 주는 영향은 작지만 수가 압도적으로 많아 최종적으로 큰 영향을 끼치는 easy negative loss가 존재한다. 이를 해결하기 위해서 Hard negative example에는 큰 가중치를 주고, Easy negative example에는 더 작은 가중치를 반영하는 Focal loss function이 사용된다.
3. YOLOv3
1) Bounding box prediction
Bounding box coordinate prediction
- YOLOv3는 Dimension clusters로 생성된 Anchor boxes을 사용하여 bounding box 좌표 예측을 수행한다.
- Box의 좌표 중점 x, y에 대해서 offsets을 사용하며, box 좌표는 다음의 식으로 정의된다.

=> 최종적으로 예측하는 box 좌표는 (t_x, t_y, t_w, t_h)이다.
- x, y에 대해서 offsets을 사용하는 이유는 다음과 같다.

Objectness score prediction
- YOLOv3는 추론할 때, 각 box마다 logistic regression을 이용하여 Objectness score을 예측한다.
- 학습을 진행할 때는 추론 시와 다르게, IOU threshold = 0.5로 설정하고 Ground-truth box와 가장 많이 겹치는 box = 1, 그 외의 box는 무시하는 방식으로 수행한다.

2) Class Prediction
- YOLOv3는 객체에 대한 클래스를 예측할 때, 각 클래스마다 독립적인 logistic classifiers(이진분류기)을 사용하여 클래스를 예측한다.
- 이러한 방식을 취하는 이유는 Open Images 데이터셋과 같은 복잡한 도메인을 가진 데이터을 다루기 수월하기 때문이다.
(Open Images Dataset : Woman, Person과 같은 overlaps labels가 다수 존재하는 dataset) - 또한, Logistic classifiers을 사용하여 기존 Softmax의 문제점(반드시 하나의 class를 가진다고 가정하는 문제)을 개선할 수 있다.

- 이 뿐만 아니라, Multi-Labeling도 수행할 수 있다.

3) YOLOv3 architecture와 특징
YOLOv3 구조
- 3-scales features에서 각각 예측을 진행한다.

- 출력층에서 각각의 scales의 feature맵을 concat하면서 최종 출력을 만들어낸다.

Bounding box priors
- YOLOv3에서는 9개의 clusters와 3개의 scales을 임의로 선택하고 cluster을 scale 간 균등하게 나누는 방식으로 Bounding box priors을 구성한다.
(즉, 9개의 clusters을 3-scales feature map에 맞게 각각 scales을 적용하여 구성) - Ex. COCO dataset의 9개 cluster (각 feature map당 3개 씩) : (10x13), (16x30), (33x23), (30x61), (62x45), (59x119), (116x90), (156x198), (373x326)

Feature maps 각 cell별 구성

4) Feature Extractor
Feature Extractor Network
- YOLOv3는 이미지의 feature을 추출하는 네트워크로 DarkNet-53을 사용하였다.
- DarkNet-53은 YOLOv2와 DarkNet-19의 방식을 hybrid한 방법으로 Residual network stuff가 사용되었다.
- 또한, '53'은 총 53개의 Convolution layer가 사용되었다는 뜻이다.
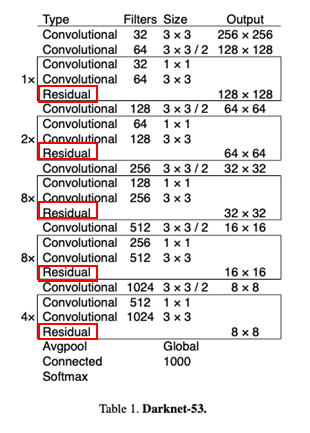
5) 학습
학습방법
- Full size의 image에 대해 학습 (단순히 Full size image만 사용하고 다른 기법들은 사용하지 않음)
- Multi-Scale training 적용하고, data augmentation, batch normalization 등 사용하였다.
- Darknet neural network framework로 학습과 테스트를 진행하였다.
YOLOv3의 Loss function 분석

4. 실험 및 문제점 분석
1) 실험
Backbone Network 별 성능 비교 (입력 이미지 사이즈 : 256 x 256)

- DarkNet-53은 ResNet-101보다 좋은 성능, 빠른 속도를 가진다.
COCO dataset에 대한 모델 성능 비교

- YOLOv3는 SSD 보다 빠르고 정확하다. (by COCO metric)
- RetinaNet보다 정확성은 떨어지지만 속도는 3.8배 빠르다.
- Small object detection에 대해서 YOLOv2에 비해 성능이 향상되었다.
Object Detection models의 속도-mAP50 그래프

- 당시 state-of-art 모델과 비교했을 때, 속도와 정확성 모두 우수하다.
2) 문제점 분석
Linear Activation 사용시 문제점
- 문제점
- Logistic activation 대신 linear activation을 사용하여 offset x, y를 예측하니 mAP가 하락하는 문제가 발생
- 사용이유 추측
- 다중 출력이 가능한 linear activation 사용으로 모델의 사이즈를 줄이고자 함.
- 즉, 속도를 더 향상시키고 모델을 단순화 하기 위함.
- 문제 발생 이유 추측
- linear activation은 back-propagation이 불가능 즉, 학습이 불가능하다.=> 오차↑mAP↓
- 또한 Residual 기법을 적용하는 이유가 더 깊은 네트워크를 구성하여 feature을 더 잘 추출하기 위함인데 Linear activation을 사용하면 이러한 이점을 활용하지 못하게 된다.
Focal Loss 사용 시 문제점
- 문제점
- Object와 background의 데이터가 불균형하기 때문에 이를 해결하기 위해서 Focal loss을 사용했으나, 오히려 mAP가 하락.
- 문제 발생 원인 추측
- YOLO는 Multi-part loss function을 사용하고 있다. 따라서 loss function을 밸런싱하려면 Classification 뿐만 아니라, coordinates, objectness에 대한 밸런싱도 함께 고려해야한다. 그렇기에 classification만 밸런싱하는 것은 오히려 언밸런싱하게 만드는 요소가 될 수 있다.

Dual IOU Threshold 사용 시 문제점
- 문제점
- Faster R-CNN와 같이 복수의 IOU Threshold를 사용해보았으나, 성능의 하락이 있었다.
- 사용 이유 추측
- Faster R-CNN에서 Anchor boxes을 사용했기 때문에 그와 마찬가지로 같은 IOU Threshold 방식을 사용
- 문제 발생 이유 추측
- Faster R-CNN은 실험을 통해서 최적의 Anchor boxes scales 설정 => 이에 맞는 IOU Threshold 설정하였다.
- YOLOv3은 k-means을 통해서 최적의 Anchor boxes scales 설정 + 3-scales feature map 사용
- 따라서, Faster R-CNN과 같은 방식을 적용하면 오차가 발생할 수 밖에 없다.
Reference
[1] Joseph Redmon. Ali Farhadi. YOLOv3: An Incremental Improvement. IN CVPR, 2018.
[2] 김정섭. https://www.youtube.com/watch?v=jqykPH3jbic
'Paper Review > Object Detection' 카테고리의 다른 글
| [Paper Review - Object Detection] 5. YOLO9000 : Better, Faster, Stronger (0) | 2023.02.13 |
|---|---|
| [Paper Review - Object Detection] 4. YOLOv1 (0) | 2023.01.25 |
| [Paper Review - Object Detection] 3. Faster R-CNN (0) | 2023.01.21 |
| [Paper Review - Object Detection] 2. Fast R-CNN (0) | 2023.01.15 |
| [Paper Review - Object Detection] 1. R-CNN (0) | 2023.01.10 |



