
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Linux build
- Carla
- 논문 분석
- 논문분석
- TensorFlow Object Detection Model Build
- 개발흐름
- VOC 변환
- AI Security
- TensorFlow Object Detection 사용예시
- 객체 탐지
- DOTA dataset
- CARLA simulator
- Git
- 리눅스 빌드
- TensorFlow Object Detection Error
- 기능과 역할
- DACON
- object detection
- Branch 활용 개발
- paper review
- 커스텀 애니메이션 적용
- TensorFlow Object Detection API install
- Custom Animation
- Paper Analysis
- Object Detection Dataset 생성
- Towards Deep Learning Models Resistant to Adversarial Attacks
- Docker
- InstructPix2Pix
- 사회초년생 추천독서
- 크롤링
Archives
- Today
- Total
JSP's Deep learning
[Crawling Practice] 1. 메이플스토리 인벤/자유게시판의 데이터 수집 본문
Data Processing/Crawling Practice
[Crawling Practice] 1. 메이플스토리 인벤/자유게시판의 데이터 수집
_JSP_ 2022. 5. 24. 17:38오늘은 막무가내 크롤링 첫 시작하는 날~!
막무가내 크롤링이긴해도 이왕이면 관심있는 데이터를 수집해보는게 정신건강에 좋을 것 같다!
그래서 선정한 주제는 바로 "메이플스토리 인벤 자유게시판 데이터 수집"
선정 이유는... 평소에 자연어 처리에 관심이 있기도 했고... 옛날에 자주하던 게임이 메이플이었기도 하고... 뭐 그렇다!
그럼 바로 코드로 들어가자
1. 패키지 Load
import sys # 시스템
import os # 시스템
# 데이터 처리
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup # html 전처리
from selenium import webdriver # 웹 브라우저 자동화
from selenium.webdriver.common.keys import Keys # 웹 드라이버 동작 명령
import chromedriver_autoinstaller # 크롬 브라우저
from tqdm import tqdm_notebook # 시간 측정
import time # 시간 지연
import warnings # 경고문 무시
warnings.filterwarnings('ignore')크롤러 동작에 필요한 각종 패키지들을 로드한다.
여기서 chromedriver_autoinstaller는 cmd 창에서 pip install chromedriver_autoinstaller로 설치해야한다.
2. 게시글 URL 수집
* url을 수집하는 이유는 url을 통해 접속하여 데이터 수집을 간편화하기 위함이다.
* element의 위치는 대부분 css_selector을 통해서 지정하였다.
query_txt = '메이플 인벤'
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path) # 크롬 브라우저
# 구글 접속
driver.get('http://www.google.com')
time.sleep(2) # 2초간 정지
# 메이플 인벤 검색
element = driver.find_element_by_css_selector(".gLFyf.gsfi") # css selector
element.send_keys(query_txt) # query_txt는 위에서 입력한 키워드
element.submit()
time.sleep(1)
# 메이플 인벤 클릭
driver.find_element_by_css_selector(".yuRUbf .LC20lb.MBeuO.DKV0Md").click( )
time.sleep(1)
# 자유게시판 이동
driver.switch_to_window(driver.window_handles[0])
driver.execute_script("window.scrollTo(0, 500)")
driver.find_element_by_xpath('//*[@id="mapleBody"]/div[1]/section/article/section[1]/div[3]/ul[4]/li[1]/span/a/span').click()
time.sleep(1)
# 게시글 url 수집
url_list = []
title_list = []
# URL_raw 크롤링 시작
articles = ".text-wrap .subject-link"
article_raw = driver.find_elements_by_css_selector(articles)
# 크롤링한 url 정제 시작
for article in article_raw:
url = article.get_attribute('href')
url_list.append(url)
time.sleep(1)
# 제목 크롤링 시작
for article in article_raw:
title = article.text
title_list.append(title)
print(title)
print("")
print('url갯수: ', len(url_list))
print('title갯수: ', len(title_list))
# 수집된 url_list, title_list로 판다스 데이터프레임 만들기
df = pd.DataFrame({'url':url_list, 'title':title_list})
# 저장하기
df.to_csv("board_url.csv", encoding='utf-8-sig')
3. 게시글 데이터 수집
* 앞서 수집한 URL을 바탕으로 수집을 진행한다.
# 수집했던 url 불러오기
url_load = pd.read_csv("board_url.csv")
url_load = url_load.drop("Unnamed: 0", axis=1) # 불필요한 칼럼 삭제
dict = {} # 전체 크롤링 데이터를 담을 그릇
# 수집할 글 갯수 정하기
number = 40
# 수집한 url 돌면서 데이터 수집
for i in tqdm_notebook(range(2, number)): # 처음 2개의 게시글은 공지이므로 제외
# 글 띄우기
url = url_load['url'][i]
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path)
driver.get(url) # 글 띄우기
# 크롤링
# 예외 처리
try :
target_info = {} # 개별 게시판 내용을 담을 딕셔너리 생성
# 제목 크롤링 시작
overlays = ".articleTitle"
tit = driver.find_element_by_css_selector(overlays) # title
title = tit.text # 셀레늄 덩어리 안의 텍스트 가져오기
title
# 글쓴이 크롤링
overlays = ".nickname"
nick = driver.find_element_by_css_selector(overlays) # nickname
nickname = nick.text
# 날짜 크롤링
overlays = ".articleDate"
date = driver.find_element_by_css_selector(overlays) # datetime
datetime = date.text
# 내용 크롤링
overlays = ".contentBody"
contents = driver.find_elements_by_css_selector(overlays) # contents
content_list = []
for content in contents:
content_list.append(content.text)
content_str = ' '.join(content_list) # content_str
# 글 하나는 target_info라는 딕셔너리에 담기게 되고,
target_info['title'] = title
target_info['nickname'] = nickname
target_info['datetime'] = datetime
target_info['content'] = content_str
# 각각의 글은 dict라는 딕셔너리에 담기게 됩니다.
dict[i] = target_info
time.sleep(1)
# 크롤링이 성공하면 글 제목을 출력하게 되고,
print(i, title, nickname)
# 글 하나 크롤링 후 크롬 창을 닫습니다.
driver.close()
# 에러나면 현재 크롬창을 닫고 다음 글(i+1)로 이동합니다.
except:
# print("에러",i, title)
driver.close()
time.sleep(1)
continue
# 중간,중간에 파일로 저장하기
if i==30 or i==50 or i==80:
# 판다스 데이터프레임으로 만들기
result_df = pd.DataFrame.from_dict(dict, 'index')
# 저장하기
result_df.to_csv("board_content.csv", encoding='utf-8-sig')
time.sleep(3)
print('수집한 글 갯수: ', len(dict))
print(dict)
# 판다스로 만들기
result_df = pd.DataFrame.from_dict(dict, orient='index')
result_df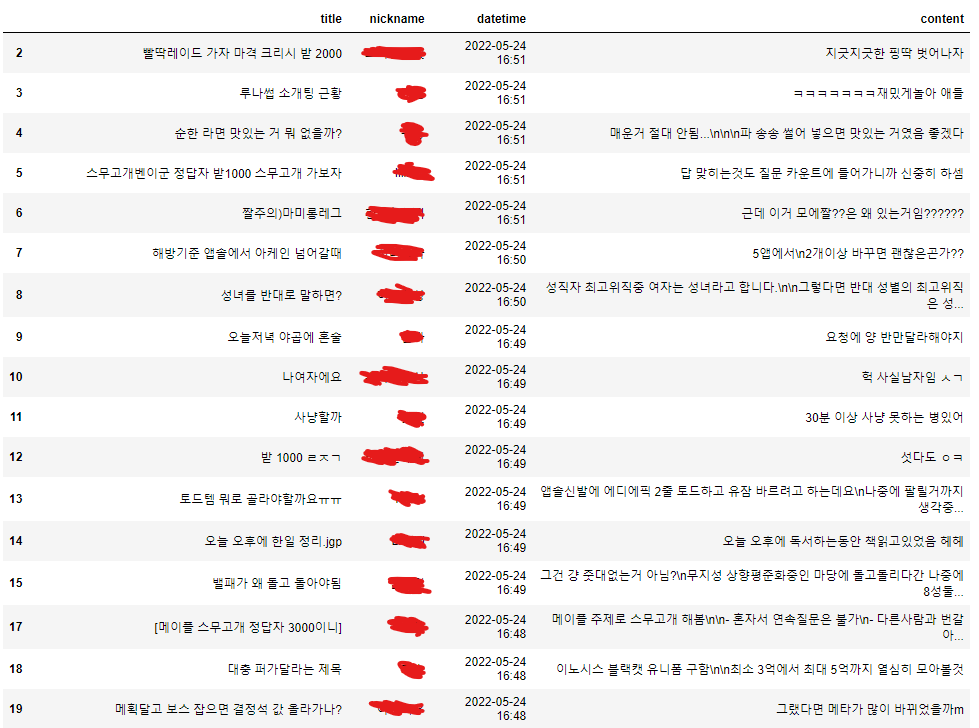
결론
- 데이터가 아주 잘 수집되었다.
- 게시글 내용의 전처리 작업은 진행하지 않았다.
- 확실히 html에 대해 조금 공부하니 크롤링이 조금 더 쉬운 것 같다.
'Data Processing > Crawling Practice' 카테고리의 다른 글
| [Crawling Practice] 3. 인스타그램 크롤링 (0) | 2022.05.26 |
|---|---|
| [Crawling Practice] 2. 프리스타일2/자유게시판 크롤링 (0) | 2022.05.25 |
| [Crawling Practice] 0. 프롤로그 (0) | 2022.05.24 |
'Data Processing/Crawling Practice' Related Articles
more


Comments