
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- InstructPix2Pix
- Git
- TensorFlow Object Detection Error
- DOTA dataset
- Object Detection Dataset 생성
- AI Security
- 크롤링
- Custom Animation
- 커스텀 애니메이션 적용
- Carla
- 논문분석
- TensorFlow Object Detection 사용예시
- 리눅스 빌드
- Towards Deep Learning Models Resistant to Adversarial Attacks
- CARLA simulator
- object detection
- 개발흐름
- VOC 변환
- Paper Analysis
- Linux build
- Docker
- 논문 분석
- Branch 활용 개발
- paper review
- 기능과 역할
- TensorFlow Object Detection Model Build
- 사회초년생 추천독서
- DACON
- 객체 탐지
- TensorFlow Object Detection API install
- Today
- Total
JSP's Deep learning
[Paper Review - NLP] Transformer : Attention Is All You Need 본문
[Paper Review - NLP] Transformer : Attention Is All You Need
_JSP_ 2023. 5. 2. 17:011. 언어모델의 역사

- Transformer의 등장을 통해서 RNN의 입력 시퀀스 길이에 따른 모델 복잡도, 기울기 소실 문제 등을 개선하였다.
- Transformer는 거대 언어 모델(Large Language Model)의 토대가 되었다.
- 현재(2023년)에는 범용 인공지능에 한 발짝 다가선 ChatGPT가 화두에 올랐다.
2. Transformer
2.1. 구조
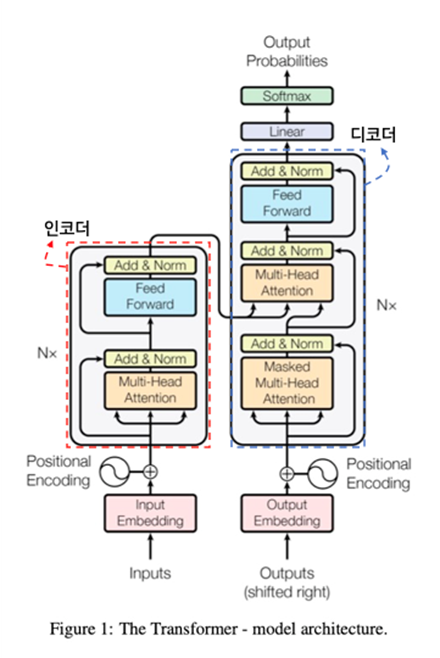
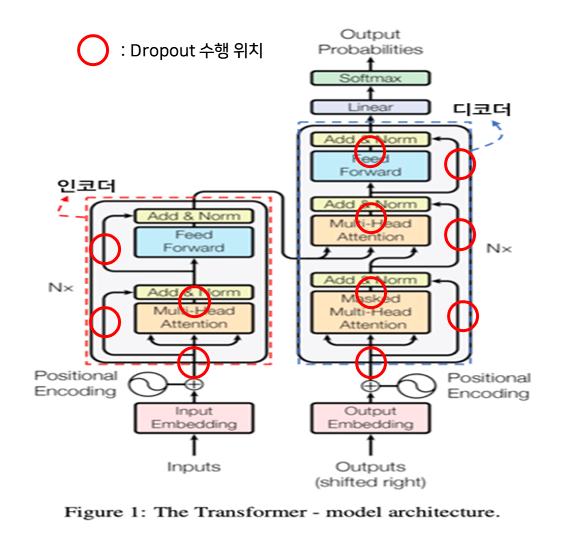
2.1.1. 전체 구조
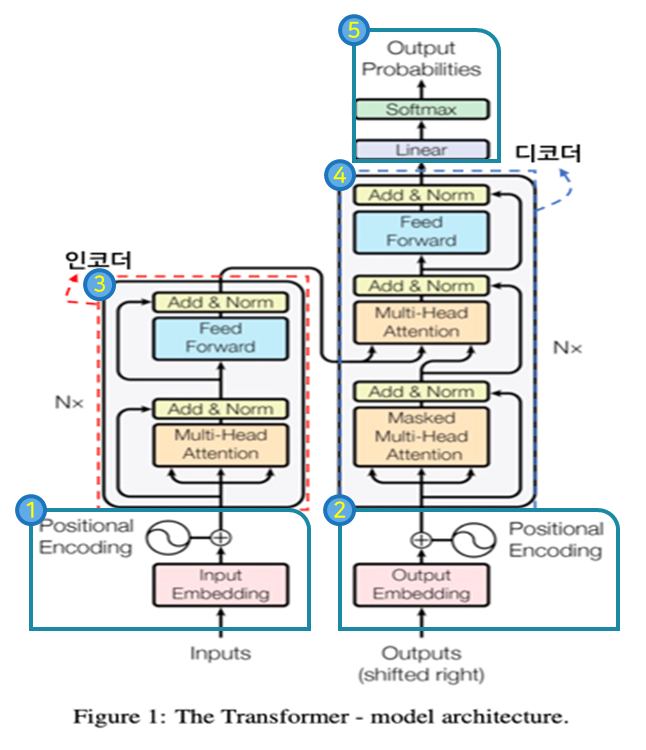
- Transformer의 구조는 크게 5가지로 나눌 수 있다.
- 인코더 입력
- 전처리된 입력 문장에 대한 임베딩을 수행한다.
- 포지션 인코딩을 통해 위치 값을 반영한다.
- 디코더 입력
- 디코더의 입력 문장에 대한 임베딩 및 포지션 인코딩을 수행한다.
- 학습시에는 정답문장, 추론(번역 task)시에는 시작 토큰이 최초 입력으로 주어진다.
- 인코더
- 총 N개(본문 6개)의 인코더가 서로 연결된 방식으로 구성된다.
- 임베딩된 입력 문장에 대해 Self-Attention을 수행하여 입력 문장의 토큰들 간의 관계를 고려한다.
- 최종 출력은 모든 디코더의 Multi-Head Attention의 입력 값(Key, Value)로 사용된다.
- 디코더
- 총 N개(본문 6개)의 디코더가 서로 연결된 방식으로 구성된다.
- 임베딩된 디코더의 입력 문장에 대해서 Self-Attention을 수행한다.
- Masked Multi-Head Attention을 통해 예측할 단어의 이전 단어들과의 문장관계만 고려한다.
- 인코더의 출력 값을 받는 Multi-Head Attention을 통해서 문장을 예측하는데 입력 문장을 고려한다..
- 출력
- 디코더의 최종 출력 값을 이용하여 Softmax을 통해 타깃 토큰의 확률 값을 출력한다.
2.1.2 인코더 구조

- 인코더의 구조는 세부적으로 4가지로 구성된다.
- Residual connection
-
입력 값에 대한 원본을 그대로 가져옴
-
최초 입력에 대한 의미를 보존
-
장기기억에 대한 문제해결
-
- Multi-Head Attention
-
인코더의 입력 값에 대한 Attention 수행
-
토큰들 간의 관계 학습
-
- Add & Normalization
-
각 Sub layer Network의 출력과 Residual connection을 거친 값에 대해 Add 연산과 Normalization 수행
-
입력 문장에 각 토큰들 간의 관계 값 반영
-
- Position-wise Feed Forward Networks
-
2개의 fully-connected layer로 구성
-
Multi-Head Attention을 거쳐 모든 문장 간의 의미가 반영된 벡터에 대해서 값을 재정립
-
2.1.3. 디코더 구조
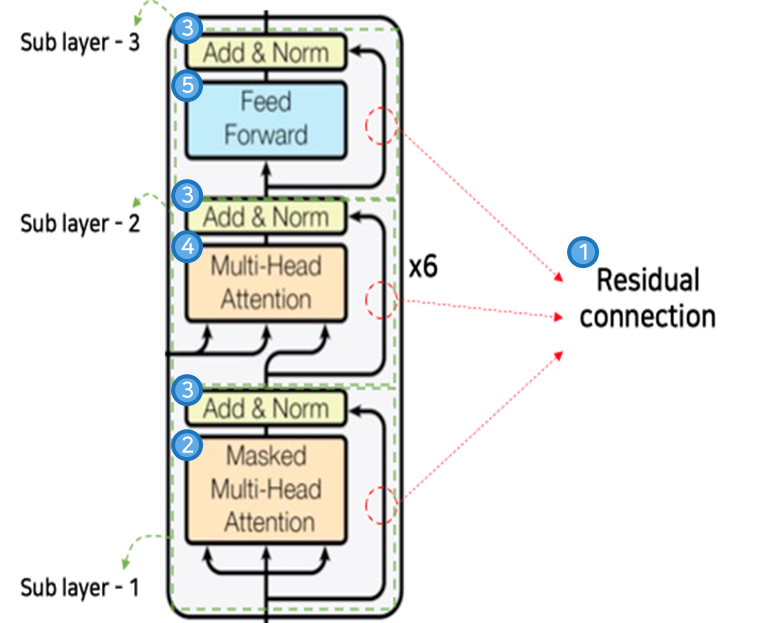
- 디코더의 구조는 세부적으로 5가지로 나뉜다.
- Residual connection
-
입력 값에 대한 원본을 그대로 가져옴
-
디코더 입력에 대한 의미를 보존
-
장기기억에 대한 문제해결
-
- Masked Multi-Head Attention
-
디코더의 입력에 대해 Masking 후 Attention 수행
-
타겟 토큰의 이전 토큰들의 의미만 반영
-
- Add & Normalization
-
각 Sub layer Network의 출력과 Residual connection을 거친 값에 대해 Add 연산과 Normalization 수행
-
디코더 초기 입력 값에 각 Sub layer의 출력 값 누적 반영
-
- Multi-Head Attention
-
인코더의 최종 출력을 반영하여 Multi-Head Attention 수행
-
입력 문장의 의미를 반영한 디코딩
-
- Position-wise Feed Forward Networks
-
2개의 fully-connected layer로 구성
-
Multi-Head Attention을 거쳐 모든 문장 간의 의미가 반영된 벡터에 대해서 값을 재정립
-
2.2. 연산방법
2.2.1. Attention 개요

- Attention이란, 입력문장의 각 토큰과 예측할 타겟 토큰과의 의미관계를 개별적으로 나타낼 수 있도록 가중치를 부여하는 기법이다. 즉, 예측할 토큰이 입력문장의 어느 토큰에 가장 집중해야 하는지 알려주는 기법(가중치 부여)이므로 Attention 기법이라고 한다.

- 위의 그림은 Self-Attention의 세부구조이며, 크게 3가지로 나뉜다.
- Scaled Dot-Product Attention
-
한 쌍의 (Query, Key, Value)에 대한 Attention 수행
-
선택적으로 Mask 수행
-
- Multi-Head Attention
-
h개의 (Query, Key, Value)에 대한 Scaled Dot-Product Attention 수행
-
- Masked Multi-Head Attention
-
h개의 (Query, Key, Value)에 대한 Masked Scaled Dot-Product Attention 수행
-
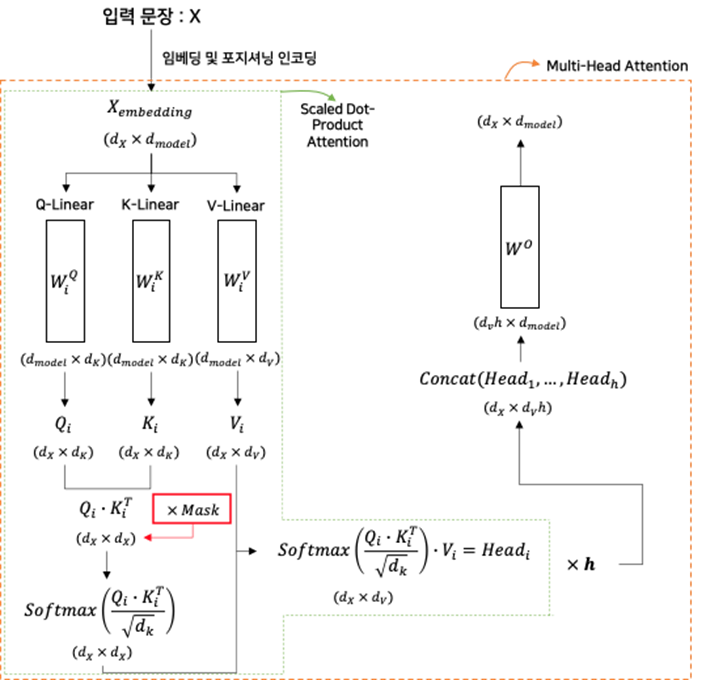
2.2.2. Scaled Dot-Product Attention
수식
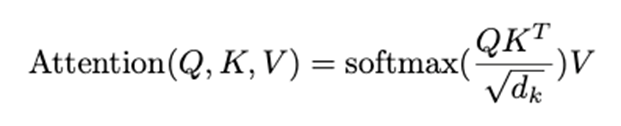
수식과 구조
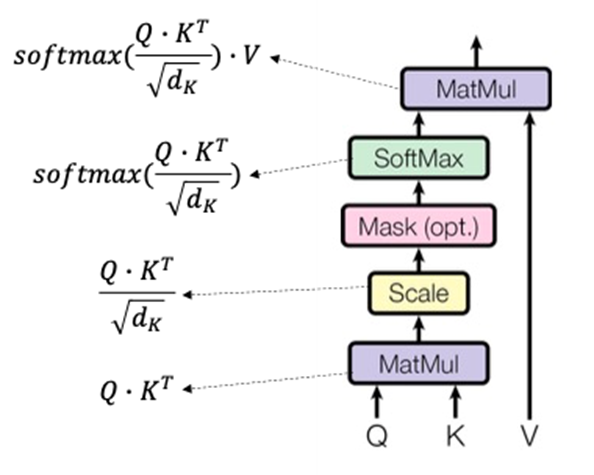
- Scaled Dot-Product Attention은 d_k의 차원을 가지는 Query, Key, d_v의 차원을 가지는 Value을 입력으로 받아 연산을 수행한다.
- 수행순서는 다음과 같다.
- Query와 Key^T을 내적
- √(d_k )의 값으로 나누어 내적 값의 크기를 조절
(큰 d_k의 값으로 SoftMax의 최적화가 잘 안 되는 상황을 방지) - SoftMax 연산 수행
- Value와 내적
- 즉, 다음의 과정을 통해서 입력 시퀀스 간의 의미가 반영된 Query 벡터가 출력된다.
(입력 시퀀스의 모든 위치의 토큰을 반영하여 중요한 토큰에 집중한다)
세부 연산


- Scaled Dot-Product Attention을 한번 시행하면 하나의 Head 값을 출력한다.
- Head는 Multi-Head Attention의 반복횟수인 h개만큼 존재한다.
2.2.3. Multi-Head Attention
수식

수식과 구조

- Multi-Head Attention은 Scaled Dot-Product Attention을 h번만큼 수행하는 Attention 기법이다.
- 수행순서는 다음과 같다.
- Scaled Dot-Product Attention을 h번만큼 수행
- H개의 Head에 이어 붙임
- 이후 Linear Layer의 가중치를 곱함
- 이 과정을 통해서 Query, Key, Value에 대한 다양한 표현 및 위치에 대한 정보 학습 및 반영한다.
세부 연산

- 입력 시퀀스의 차원과 출력 시퀀스의 차원이 동일하도록 설계하였다.
(인코더와 디코더를 여러 번 쌓을 수 있다) - Key, Value의 차원은 d_model의 차원을 h번만큼 나눈 것이다.
(즉, Head의 수만큼 나눈다)

2.2.4. Masked Multi-Head Attention

- Masked Multi-Head Attention은 Scaled Dot-Product Attention을 진행할 때, Masking 기법을 사용하여 Multi-Head Attention을 수행하는 기법이다.
- MMHA는 디코더의 입력 시퀀스에 대해서 수행되는데, 이는 타겟 토큰의 이전 토큰 외에는 의미를 반영하지 않기 위함이다.
세부 연산
- Mask 연산은 Scaled Dot-Product Attenion의 Scale 연산 후에 수행된다.
- Masked Multi-Head Attention은 Scaled Dot-Product Attention에서 Mask 연산이 수행되는 것 외에는 인코더의 Multi-Head Attention과 동일하다.

- Mask 연산은 SoftMax 함수의 특성을 고려하여 Masking 하고자 하는 부분이 -∞ 인 Mask 행렬을 곱하여 수행된다.
- Mask 연산이 수행된 시퀀스 벡터에 SoftMax 연산을 수행하면 Masking 된 부분은 0에 가까운 값이 된다.
(즉, Attention을 진행할 때, 영향을 주지 못하게 한다)
2.3. 구조별 Attention 기법
2.3.1. 인코더의 Attention : “Multi-Head Attention”
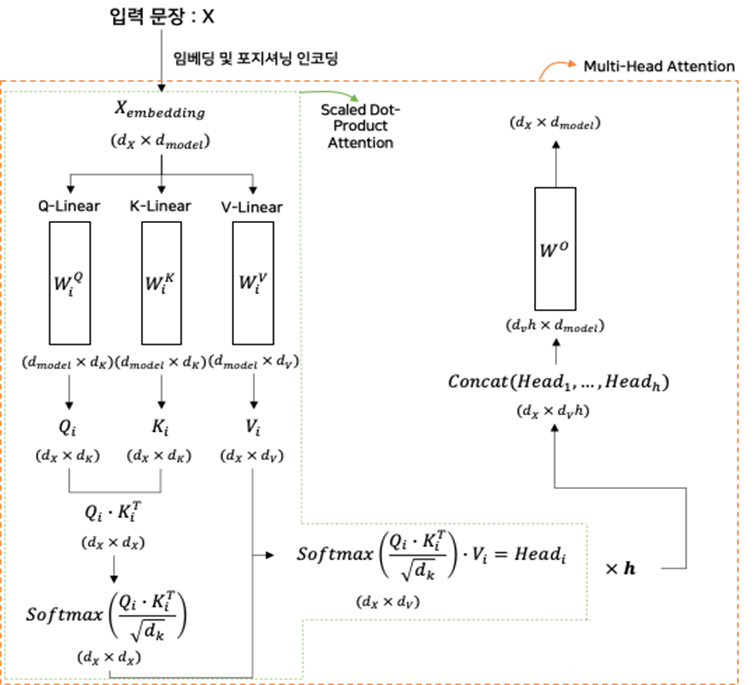
2.3.2. 디코더의 Attention : “Masked Multi-Head Attention”

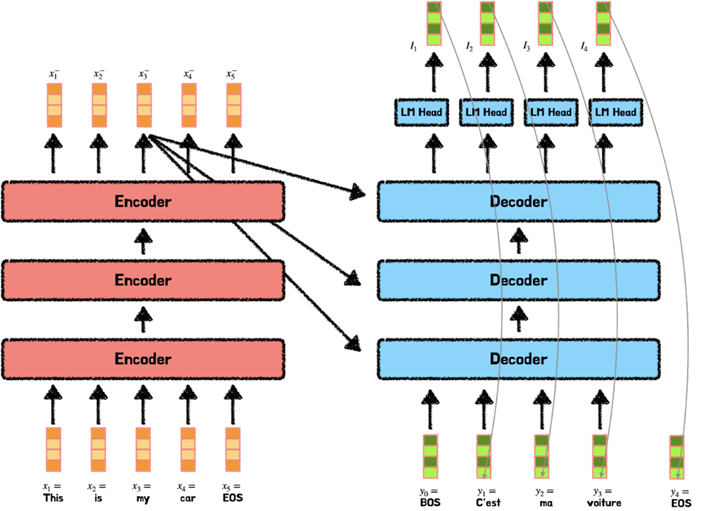
2.3.3. 디코더의 Attention : “Encoder–Decoder Multi-Head Attention”
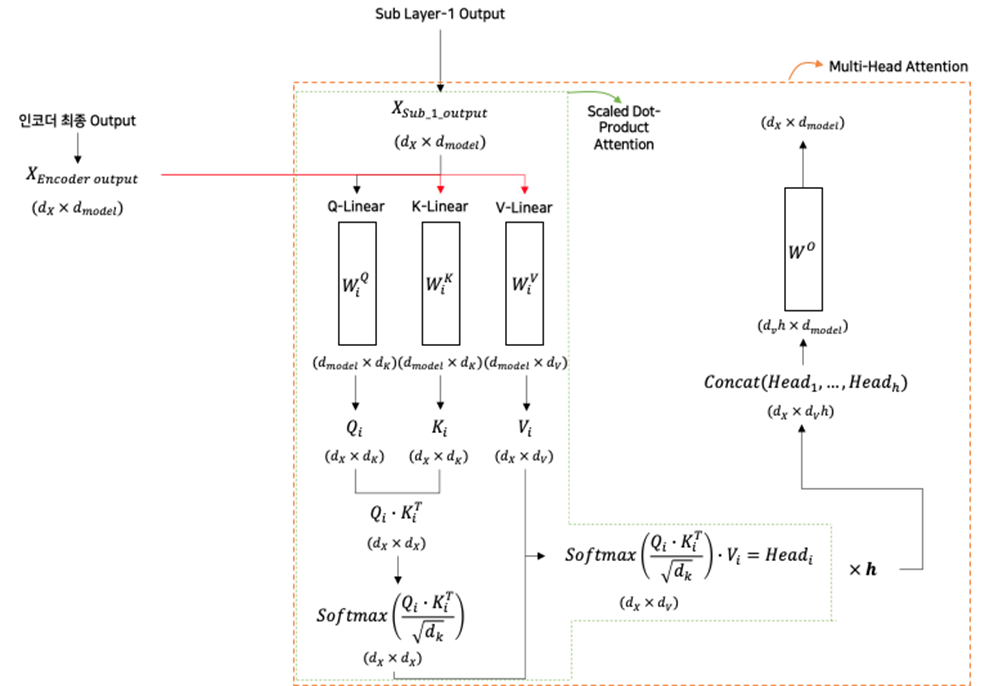
- 토큰을 예측할 때, 입력 시퀀스의 전체를 고려한다.
예시

- 인코더의 최종 출력 값은 입력 문장에 대한 모든 정보가 담겨 있기 때문에 디코더는 Multi-Head Attention 수행 시 해당 값을 반영한다.
- 이 과정을 통해서 디코더는 입력 문장을 모두 고려하여 토큰을 예측할 수 있다.
2.4. Position-wise Feed Forward Networks
수식

수식과 구조


- 수행기능
- 차원 확장(정보 세분화)
- ReLU 활성화 함수(정보 최적화)
- 차원 축소(정보 재정립)
- Multi-Head Attention의 출력 정보 구체화
2.5. Embeddings and Softmax

- Transformer의 임베딩은 토큰을 d_model의 차원을 가지는 벡터로 바꾸도록 학습된다.
- ①, ②, ③의 Linear layer는 같은 가중치를 공유한다.
(즉, 해당 Linear layer을 거쳐서 나오는 벡터는 모두 어떠한 토큰의 정보가 된다) - ③의 경우, ①, ②와 다르게 √(d_model ) 을 가중치에 곱해준다.
(Scaling으로 조정된 값을 복원) - ③의 출력 벡터는 어떠한 토큰의 정보이고 이 벡터를 SoftMax을 통해 어떠한 토큰에 가장 가까운지 확률 값으로 변환하게 된다.
2.6. Position Encoding
2.6.1. Transformer의 Position Encoding 수행방식
- Transformer는 입력 시퀀스를 순차적이 아닌, 병렬적으로 처리한다.
=> 따라서 각 토큰(단어)마다 위치정보를 따로 추가해야 한다. - Transformer는 위치정보를 반영하기 위해 Position Encoding 기법을 사용한다.
- Transformer는 위치정보를 입력 시퀀스 벡터에 더하는 방식으로 Position Encoding을 수행한다.
(Concatenate 방식 사용 시 계산비용 증가)
2.6.2. Transformer에서 요구하는 Postion Encoding 조건과 방법론
조건

방법론


Transformer에서 사용된 기법
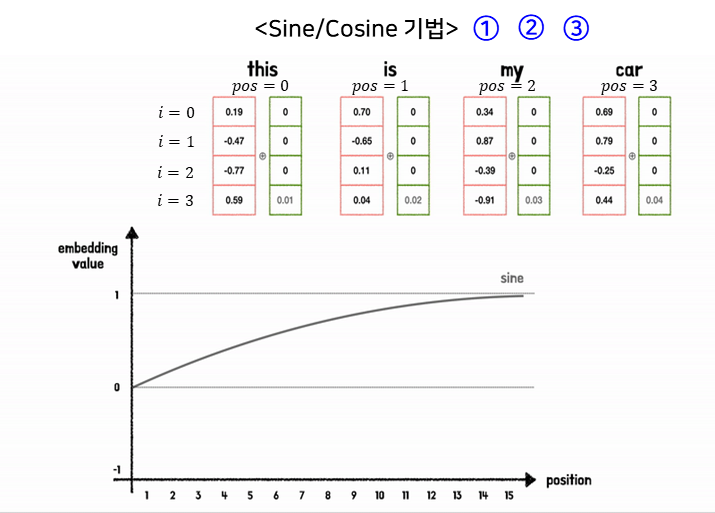
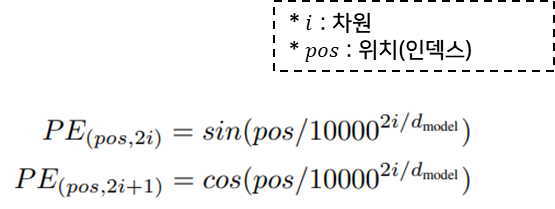
- -1 ~ 1의 값을 가지는 주기 함수로 값의 크기가 고정된다.
- 토큰의 위치와 토큰 벡터의 차원만 고려하여 위치정보가 계산된다.
- pos/10000^(2i/d_model )의 값을 통해 매우 긴 입력 시퀀스에 대해서도 위치마다 다른 값을 가지게 해 준다..
3. 학습
- 최적화 함수 : Adam(β_1=0.9, β_2=0.98,ϵ=10^(-9))
- Learning rate 스케줄링 : (warmup_step=4000)
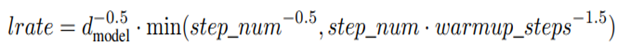
- Residual Drop Out 적용 (P_drop=0.1)
- Label Smoothing 적용 (ϵ_ls=0.1) : y_k^LS=y_k (1-a)+a/K
(K : 전체 Class 개수, k : 계산하고자 하는 Class 번호)
(즉, 원-핫에 대한 Cross-Entropy loss가 아닌
확률 분포로 변환된 정답 Label 간의 Cross-Entropy loss 계산)

4. 결과
4.1. Transformer의 효율성

- 하나의 입력 시퀀스를 인코딩 혹은 디코딩을 수행할 때, RNN에 비해 더 적은 계산양과 Layer Path 길이를 가진다.(RNN은 입력 시퀀스의 길이에 따라 n 개의 layer가 필요)
- Convolution과 비교했을 때도 마찬가지로 더 적은 계산양과 Layer Path 길이를 가진다.
4.2. Transformer의 번역 성능
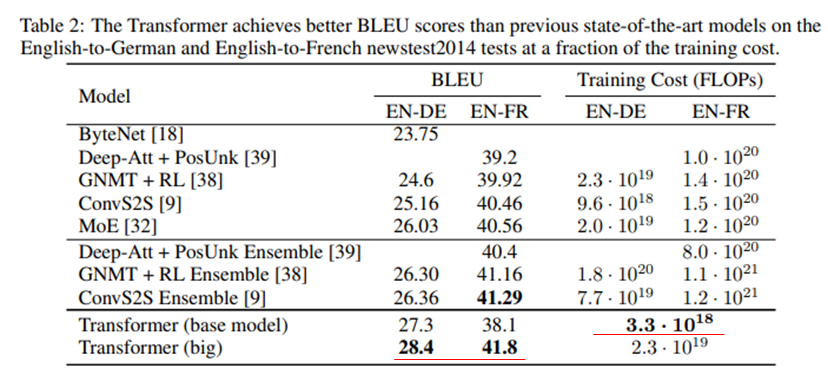
- RNN 및 CNN 기반의 언어모델보다 더 적은 계산양을 가지면서 번역에서 더 좋은 성능을 보인다.
5. 결론
- Transformer는 기존 RNN, CNN의 기울기 소실, 입력 시퀀스 길이 제약, 연산량의 문제를 개선하였다.
- Transformer는 자연어 처리뿐만 아니라 이미지, 음성에도 활용된다.
- Transformer는 현재까지 다양한 언어모델의 기반 모델이 되었다.
* Query, Key, Value란?

- Query, Key, Value는 Scaled Dot-Product Attention의 연산에서 계산되는 방식을 통해 각각의 기능(역할)이 정해진다.
(즉, 사용방식에 따라 학습을 통해 각각의 기능이 정해진다)
- Query : 다른 토큰과의 연관관계를 파악하고자 하는 토큰
- Key : 입력 시퀀스의 각 토큰의 정보
(처음 Qeury, Key의 연산을 통해 어떤 토큰이 가장 연관되는지 찾아낸다) - Value : 입력 시퀀스의 각 토큰의 값, 가중치
* SoftMax 함수 특성
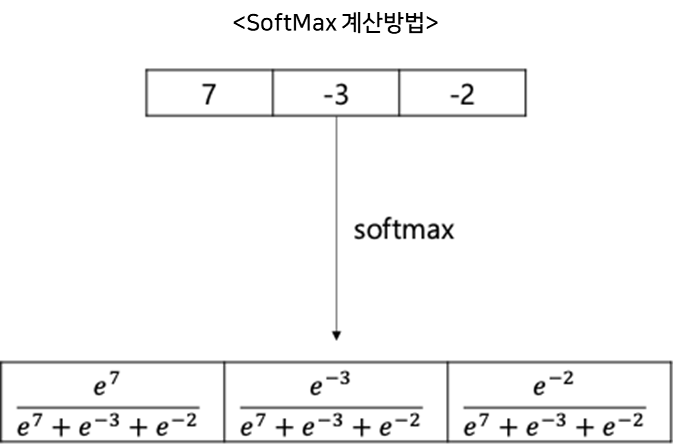
- 각 원소를 지수 함수의 x 값으로 사용

- 즉, 값이 무한대로 작아질 경우 해당 값의 SoftMax 출력은 0에 한 없이 가까워진다.
참고문헌
[1] Attention Is All You Need, IN NIPS, 2017.
[2] https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding