
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- TensorFlow Object Detection 사용예시
- Carla
- 크롤링
- DACON
- VOC 변환
- 논문 분석
- object detection
- Object Detection Dataset 생성
- 개발흐름
- Branch 활용 개발
- 리눅스 빌드
- DOTA dataset
- CARLA simulator
- 사회초년생 추천독서
- TensorFlow Object Detection Model Build
- AI Security
- 기능과 역할
- TensorFlow Object Detection Error
- InstructPix2Pix
- 객체 탐지
- 커스텀 애니메이션 적용
- 논문분석
- Git
- Paper Analysis
- Linux build
- Towards Deep Learning Models Resistant to Adversarial Attacks
- TensorFlow Object Detection API install
- paper review
- Docker
- Custom Animation
Archives
- Today
- Total
JSP's Deep learning
[Paper Review - Object Detection] 1. R-CNN 본문
1. 주요 용어
1) Region proposals
- 한 이미지에서 Object가 존재한다고 예측되는 영역을 추출하는 것
- R-CNN에서는 Selective Search 기법을 사용하여 Region proposals을 수행한다.

2) Warp
- 사전적 의미는 "왜곡"이라는 의미를 가지고 있다.
- R-CNN에서 Warp는 이미지의 사이즈를 변형한다는 의미(Reshape와 비슷하다)
- p는 context padding으로 p가 0이 아니면, 주변환경을 어느정도 포함한다.

3) Selective Search
- Region Proposals을 수행하는 기법 중 하나
- 비슷한 Pixels의 값이 있는 영역을 여러 개 선택한 다음, 중복되는 부분을 제거하여 Region Proposals을 수행한다.
- 상세한 사항은 J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013.을 참고

4) Non maximum suppression
- 직역하면 "최댓값이 아닌 것을 억제"한다는 의미가 된다.
- 즉, 하나의 Object에 대해 예측한 bounding-box에 대해서 가장 높은 스코어를 가지는 bounding-box만을 남기는 것이다.
- 방법
- 모든 BBox에 대해서 threshold(confidence-score에 관한 threshold) 이하의 confidence-score을 가지는 BBox을 모두 제거한다.
- 남은 BBox을 confidence-score 순으로 내림차순 정렬한다.
- 가장 높은 confidence-score을 가지는 BBox을 기준 box로 잡고, 다른 BBox와 IOU(Intersection Over Union)을 구한다.
- IOU가 threshold(IOU threshold) 이상인 BBox는 제거한다. (같은 Object에 대해 겹치는 BBox를 제거)

2. R-CNN 정리요약
1) R-CNN의 전체 프로세스
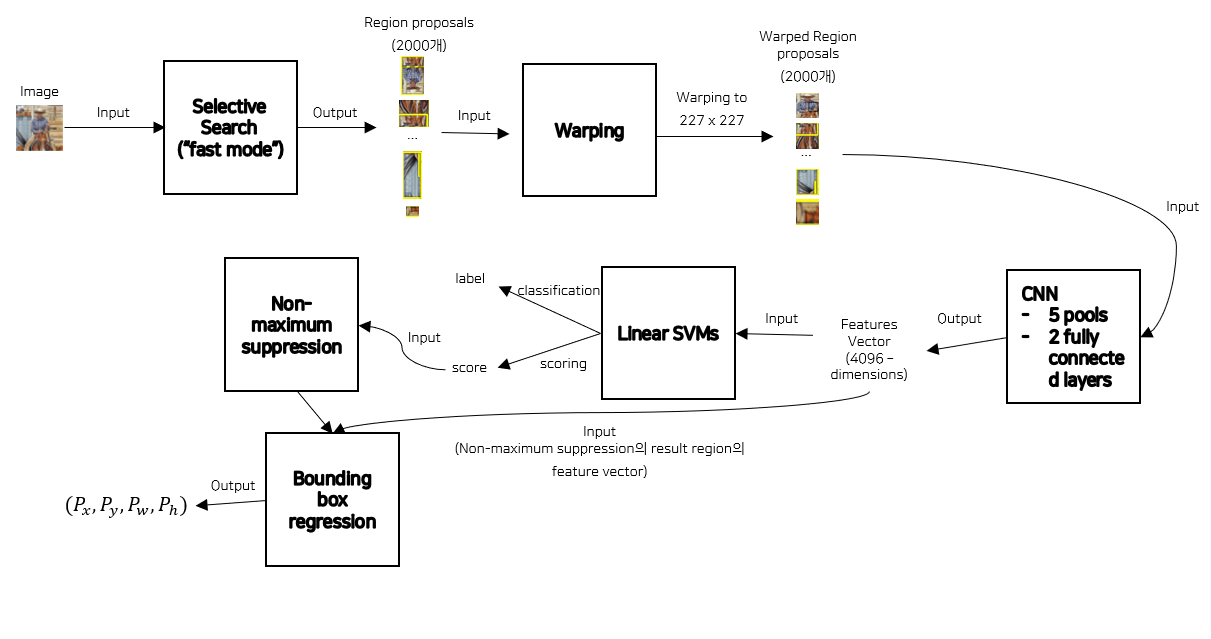
- 해당 이미지는 R-CNN의 전체 프로세스를 요약한 그림이다.
- Input : Image
- Output : Box coordinate + Predicted class + Confidence score
- CNN Architecture : VGG16
2) R-CNN을 3개의 Modules로 표현
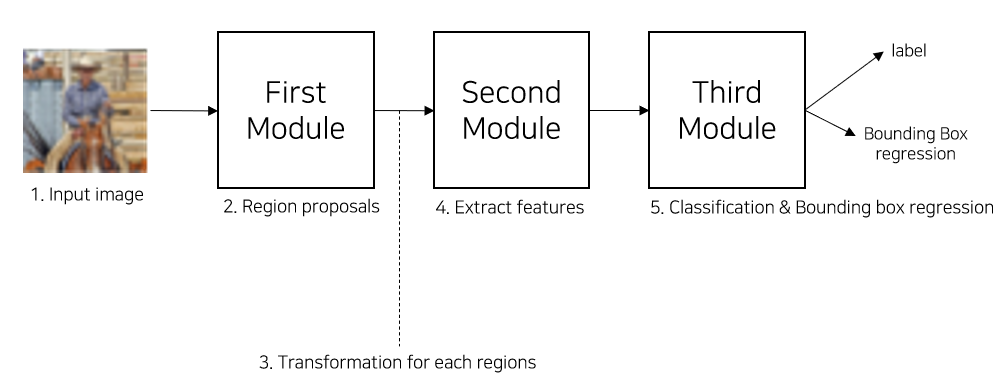
(1) First Module
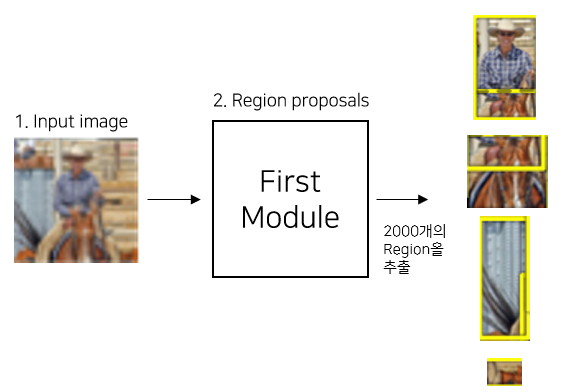
- Region proposals을 수행하는 모듈이다.
- Region proposals에 "Selective search" 기법을 사용한다.
(2) Transformation
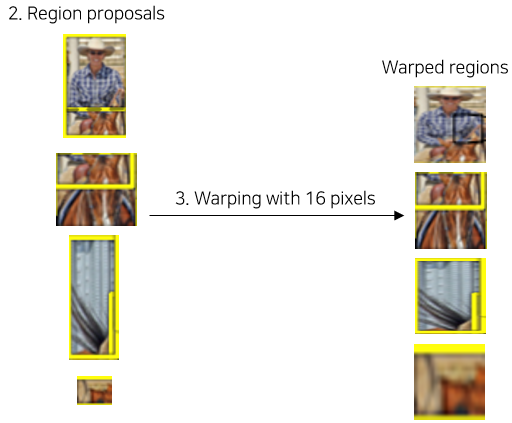
- CNN의 Input shape에 맞추기 위해서 이미지의 크기를 변형한다.
- 변환은 Warping이라고 본문에 표현되어있는데 Resize로 간단하게 생각하면 된다. (Padding 적용)
- +@
- 본문에서는 padding의 pixel p = 16으로 설정(실험적으로 높은 mAP를 가지는 값으로 선정)
- Warp size는 사용되는 CNN에 따라 달라질 수 있다.
(3) Second Module

- 각 Regions에 대해서 고정된 Feature Vector을 추출하는 모듈로 CNN을 통해서 추출한다.
- 본문에서 사용된 CNN architecture는 VGG16이다.
(4) Third Module

- Classification은 Linear SVMs을 통해서 각 Class마다 specific하게 수행된다.
- BBox regression은 Regressor을 통해서 수행된다.
- 해당 모듈에서 score는 classification 과정에서 얻어지는 confidence score이다.
- 최종적으로 BBox coordinate + label + confidence score가 output으로 주어진다.
- BBox coordinate : x, y는 BBox의 중점좌표, w,h는 BBox의 너비와 높이
3) Bounding box regression 수식
- Training Dataset 정의
- 총 N개의 (P, G)로 구성된다.
- P = (Px, Py, Pw, Ph) : 예측한 bounding box coordinate
- G = (Gx, Gy, Gw, Gh) : 정답 bounding box coordinate
- 총 N개의 (P, G)로 구성된다.
- Bounding box regression
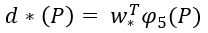
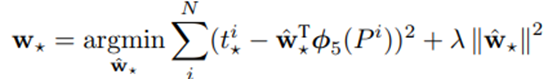
- 해당 수식은 Ridge regression 수식을 활용함.
- d*(P) : P에 대한 linear function
- P : features
- * : (x, y, w, h) 중 하나의 값
- T : Transpose 연산
- Predicted bounding box coordinate의 수식적 정의
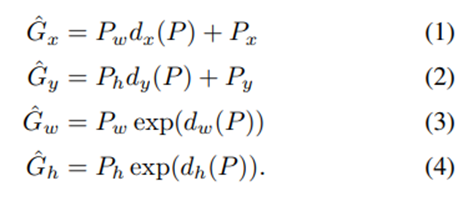
- 여기서 dx(P), dy(P)는 선형함수, dw(P), dh(P)는 로그함수를 사용하였는데 이는 dw(P), dh(P)의 값이 너무 커지는 것을 방지하기 위함이다.
- 위의 식을 Target T에 대해서 정리
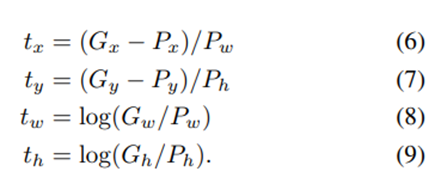
- 추가적인 사항
- γ = 1000으로 설정 (Regularization)
- (P, G)을 선정할 때, Proposal P가 ground-truth G 근처에 있어야 학습 효과가 있기 때문에 학습 데이터 셋을 구성할 때, IOU Threshold=0.6으로 설정하여 Proposal P을 선정한다.
4) Training
(1) Pre-training
- R-CNN은 ILSVRC 2012 Classification Dataset을 사용하여 CNN을 Pre-training한다.
- Pre-training은 Caffe 라이브러리를 사용하여 수행한다.
- 이 과정을 통해 학습된 CNN의 성능은 AlexNet과 비슷하다.
(2) Domain-specific fine-tuning
- Warped Region proposals을 사용하여 CNN을 fine-tuning한다.
- CNN을 fine-tuning할 때, AlexNet의 1000-way classification을 (N+1)-way classification으로 교체하는 것 외에는 바뀌지 않는다. 즉, 학습시키는 클래스의 수를 Domain에 맞추어서 fine-tuning한다.
- 여기서 +1은 background에 대한 class이다.
- Fine-tuning을 진행할 때, 데이터 셋에서 Positive example(Non-background)와 Negative example(background)의 비율을 균일하게 하기 위해서 상대적으로 적은 Positive example에 대해서 bias을 부여한다.
(3) Object category classifiers
- 방법
- CNN의 Output feature을 사용
- fine-tuning에 사용되었던 Label을 사용하여 Linear SVM을 학습
- SVM을 학습할 때, IOU Threshold = 0.3으로 설정하여 IOU < 0.3인 example은 negative example로 판단한다.
(Region proposals에서의 IOU Threshold=0.5임에 유의)- Object catergory classifiers의 학습을 진행할 때, IOU Threshold을 0.3으로 설정한 것은 grid-search을 통해서 가장 mAP의 성능이 좋은 IOU Threshold을 선택한 것이다.
- 학습시, Standard hard negative mining method을 사용
3. 실험
1) CNN Architecture에 따른 성능 비교

- O-Net의 경우 성능은 좋지만 계산 시간이 길고, T-Net의 경우 성능은 낮지만 계산 시간이 O-Net에 비해 7배 정도 빠르다.
- 두 Architecture의 차이는 Activation function에 있으며, 자세한 사항은 해당 글에서는 다루지 않는다.
2) Fine-tuning Layer 및 학습 데이터 차이 별 성능 실험
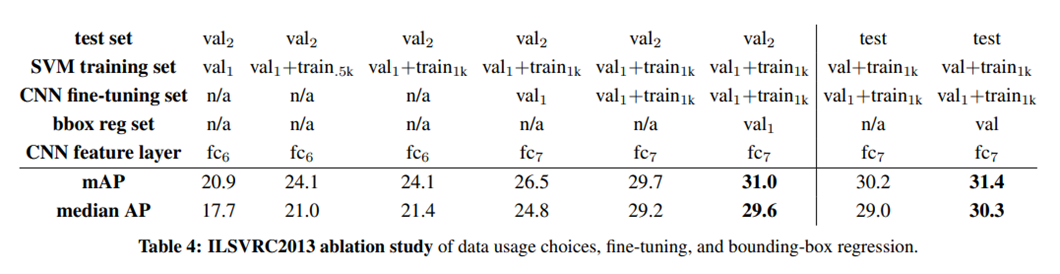
- 성능향상
- 학습 데이터 수 늘리기
- Bounding box regression 적용
- Fine-tuning 진행
- fc7 CNN feature layer 사용
3) Overfeat 모델과 비교

- 성능은 Bounding box regression을 사용한 R-CNN이 더 좋지만, 속도는 Overfeat이 9배 정도 빠르다.
4) layer-by-layer 성능 비교

- fc7 Layer 및 Bounding Box regression을 사용한 R-CNN에 Fine-tuning을 적용했을 때, 가장 성능이 우수하다.
< Reference >
[1] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5), IN CVPR, 2014.
'Paper Review > Object Detection' 카테고리의 다른 글
| [Paper Review - Object Detection] 6. YOLOv3 : An Incremental Improvement (0) | 2023.02.26 |
|---|---|
| [Paper Review - Object Detection] 5. YOLO9000 : Better, Faster, Stronger (0) | 2023.02.13 |
| [Paper Review - Object Detection] 4. YOLOv1 (0) | 2023.01.25 |
| [Paper Review - Object Detection] 3. Faster R-CNN (0) | 2023.01.21 |
| [Paper Review - Object Detection] 2. Fast R-CNN (0) | 2023.01.15 |
'Paper Review/Object Detection' Related Articles
more




Comments