
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- DOTA dataset
- 논문 분석
- Git
- Branch 활용 개발
- 논문분석
- Carla
- TensorFlow Object Detection Error
- 개발흐름
- 사회초년생 추천독서
- DACON
- object detection
- Towards Deep Learning Models Resistant to Adversarial Attacks
- Linux build
- 기능과 역할
- Object Detection Dataset 생성
- CARLA simulator
- TensorFlow Object Detection API install
- VOC 변환
- Custom Animation
- Docker
- InstructPix2Pix
- 객체 탐지
- 크롤링
- AI Security
- 커스텀 애니메이션 적용
- TensorFlow Object Detection 사용예시
- TensorFlow Object Detection Model Build
- Paper Analysis
- 리눅스 빌드
- paper review
- Today
- Total
JSP's Deep learning
[Paper Review - Object Detection] 3. Faster R-CNN 본문
[Paper Review - Object Detection] 3. Faster R-CNN
_JSP_ 2023. 1. 21. 16:01
1. Faster R-CNN 요약
1) Architecture
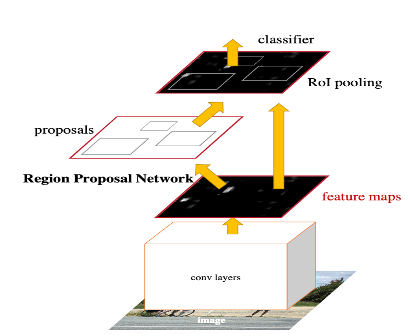
2) Faster R-CNN의 특징
- Region Proposal Network(RPN)을 이용한 Region Proposals
- RPN과 Fast R-CNN detector가 하나의 convolution feature map을 공유하도록 합친 단일 네트워크(Single Network)
- End-to-End 방식의 학습
- GPU 상에서 5 fps의 속도을 가진다.
3) Multiple scales와 sizes을 처리하기 위한 Faster R-CNN의 체계
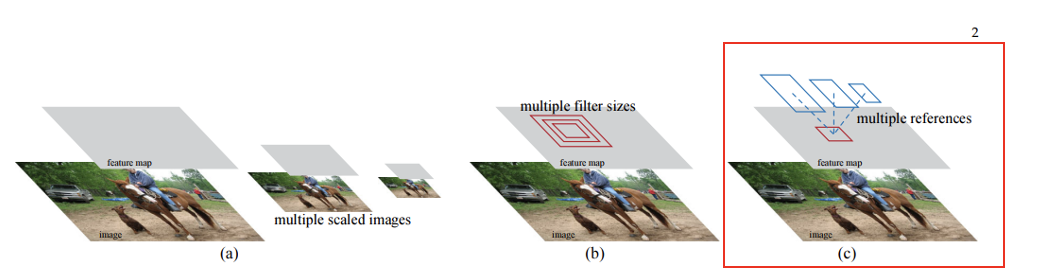
- (a) : 이미지 피라미드(Pyramids of images)에서 다양한 scales와 sizes을 가진 이미지마다 feature map을 만들어 처리하는 방법
- (b) : 필터 피라미드(Pyramids of filters)로 다양한 scales와 sizes을 가진 filters을 이용해서 원본 이미지의 feature map상에서 동작시키는 방법
- (c) : 참조 박스 피라미드(Pyramids of reference boxes)로 다양한 scales와 sizes을 가진 reference box을 이용하여 원본 이미지의 feature map 상에서 동작하는 방법.
- Faster R-CNN은 '(c)'의 방법을 사용하여 Multi scales와 sizes에 대해서 처리할 수 있도록 모델을 학습한다.
2. Faster R-CNN의 주요 용어 정리
1) Attention Mechanisms
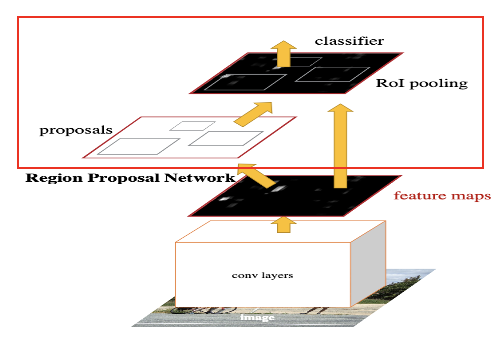
- Faster R-CNN은 RPN을 사용하여 Feature map 상에서 집중해야할 부분을 지정한다.
(Transformer의 Attention 구조와는 다른 개념으로 단순히 집중해야할 부분을 알려준다는 의미를 가진다)
2) Fully convolution network
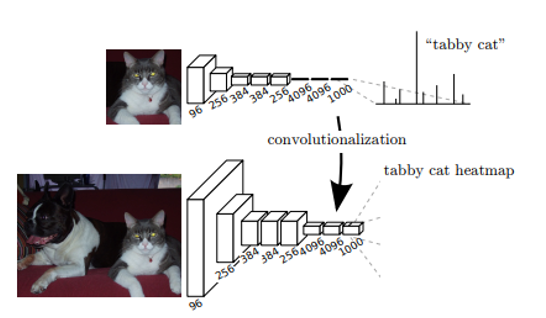
- Sematic Segmentation 모델을 위해서 Image classification에서 우수한 성능을 보인 CNN기반 모델(AlexNet, VGG16m GoogleNet 등)을 변형시킨 구조.
- 기존 CNN의 최 후단인 fully-connected layer 대신 Convolution layer을 사용하는 것.
- 기존 Fully connected layer을 사용하는 방식보다 이미지의 정보를 더 잘 보존할 수 있다는 장점이 있다.
3) End-to-End
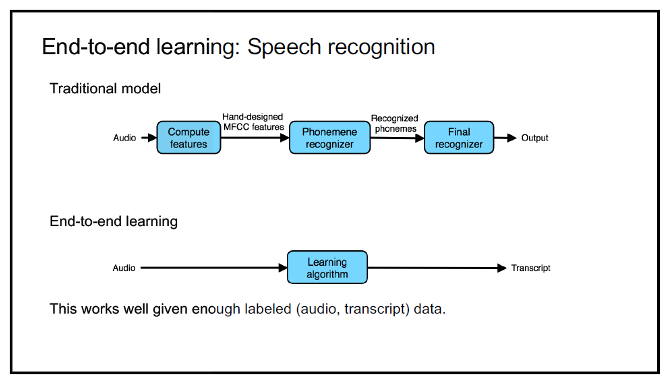
- Deep learning에서 End-to-End란 입력에서 출력까지 별도의 파이프라인 네트워크 없이 하나의 신경망으로 한 번에 처리하는 구조
- 예시)
- Non End-to-End : 얼굴 인식 시스템에서 얼굴을 인식하는 Model과 얼굴을 대조하는 Model을 따로 학습시키고 연결시켜서 사용하는 시스템은 End-to-End가 아니다.
- End-to-End : 얼굴 인식 시스템을 하나의 모델을 사용하여 결과를 출력한다면 그것은 End-to-End 구조이다.
- 여기서, 파이프라인 네트워크란 전체 네트워크를 이루는 부분 네트워크를 말한다.
4) Pyramids of image

-
입력 이미지의 크기를 단계적으로 변화(여러 scales와 aspect ratio)시켜가면서 생성된 일련의 이미지 집합(Image pyramid or Pyramids of image)
5) Anchor box & Anchor & Objectness score
(1) Anchor box
- Faster R-CNN에서 다양한 Scale과 size의 region proposals을 예측하기 위해 하나의 이미지의 feature map에서 다양한 scales과 aspect ratios의 reference boxes를 이용
- 여기서, reference box을 Anchor box라고 명명한다.
(2) Anchor
- Region Proposal Network에서 anchor boxes를 통해 생성한 region proposals
(3) Objectness score
-
객체 vs. 배경(a set of object classes vs. background)에 대해 측정한 값
- 생성된 Anchor마다 이 값을 가져서 배경인지 아닌지 구분하는 기준으로 사용된다.
6) Translation invariant
- 물체의 분류에서 물체의 위치에 대해서 Robustness을 가지는 특성
- CNN에서 translation invariant란, input의 위치가 달라져도 output이 동일한 값을 갖는 것
(convolution filter 연산을 할 때, 특정 feature의 위치가 바뀌면 해당 feature에 대한 연산 결과도 달라지게 된다) - Translation invarient을 수행하는 3가지 방법
- Max pooling
- Weight sharing & learn local features
- Softmax
(자세한 수행 방법은 https://ganghee-lee.tistory.com/43 참고)
7) "Image-centric" sampling
-
RPNs Training에서 각 mini-batch의 positive : Negative sample의 비율을 1:1로 맞추는 것
- mini-batch는 하나의 이미지로부터 추출된 positive & negative example anchors를 사용하여 구성
-
하나의 이미지에서 256개의 무작위 anchors를 추출하고 mini-batch를 구성
-
이 방법을 사용하는 이유는 Negative sample에 편향되는 것을 방지하기 위함
-
만약, Positive sample이 부족하면 negative sample로 padding
3. Faster R-CNN 본문 분석
1) Faster R-CNN 전체 Process
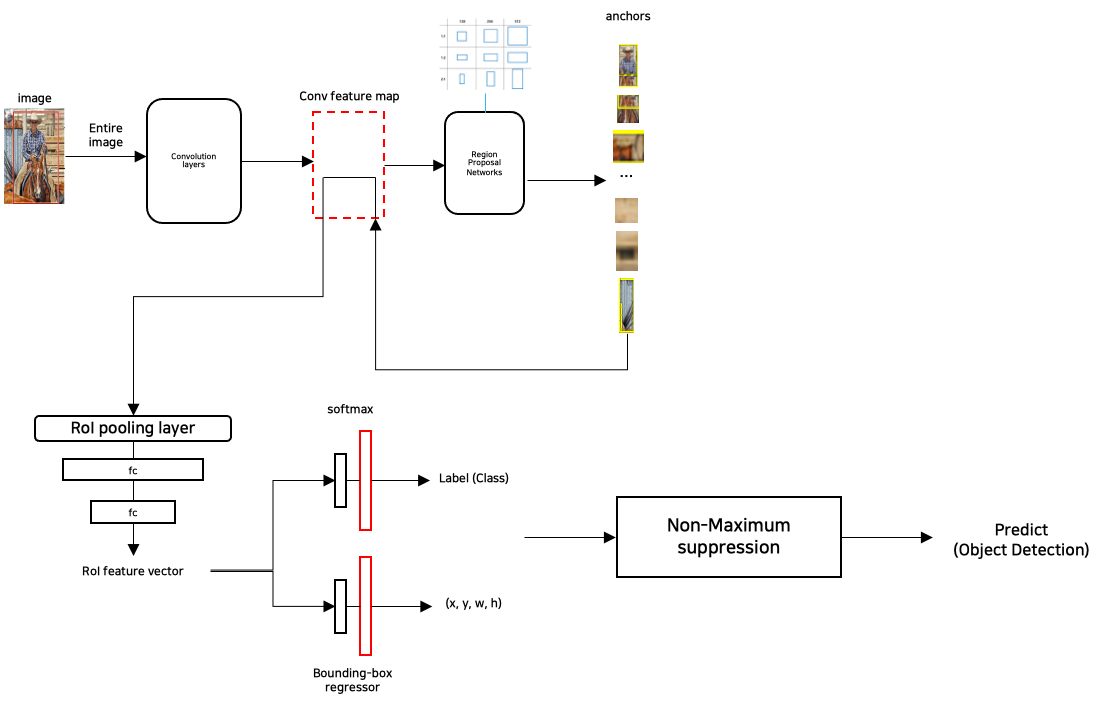
2) Faster R-CNN 세부 Process
(1) 한 이미지에 대한 Convolution Feature map 생성
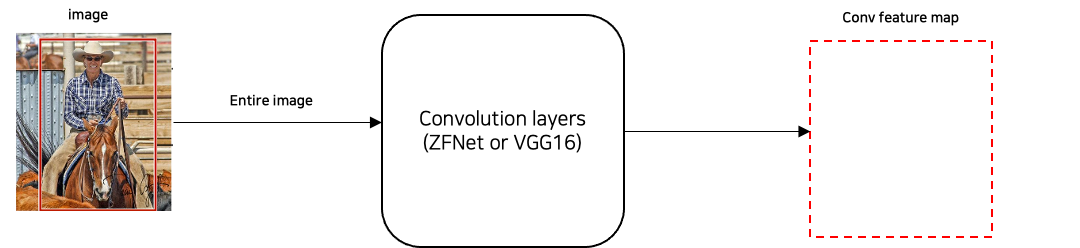
(2) RPN(Region Proposal Network)를 통한 Anchors 생성
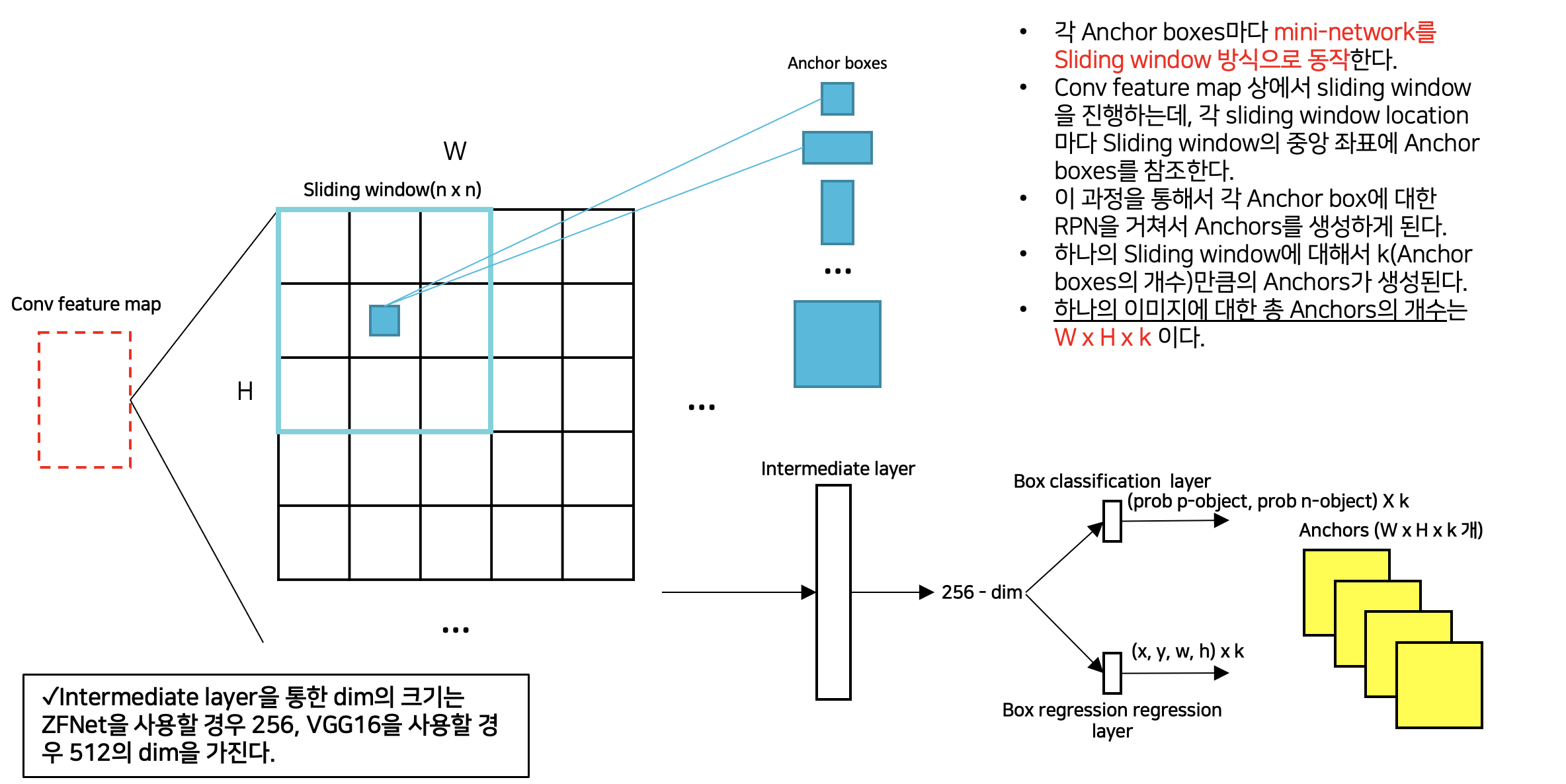
(3) RPN에서 생성된 Anchors를 사용한 ROI Pooling
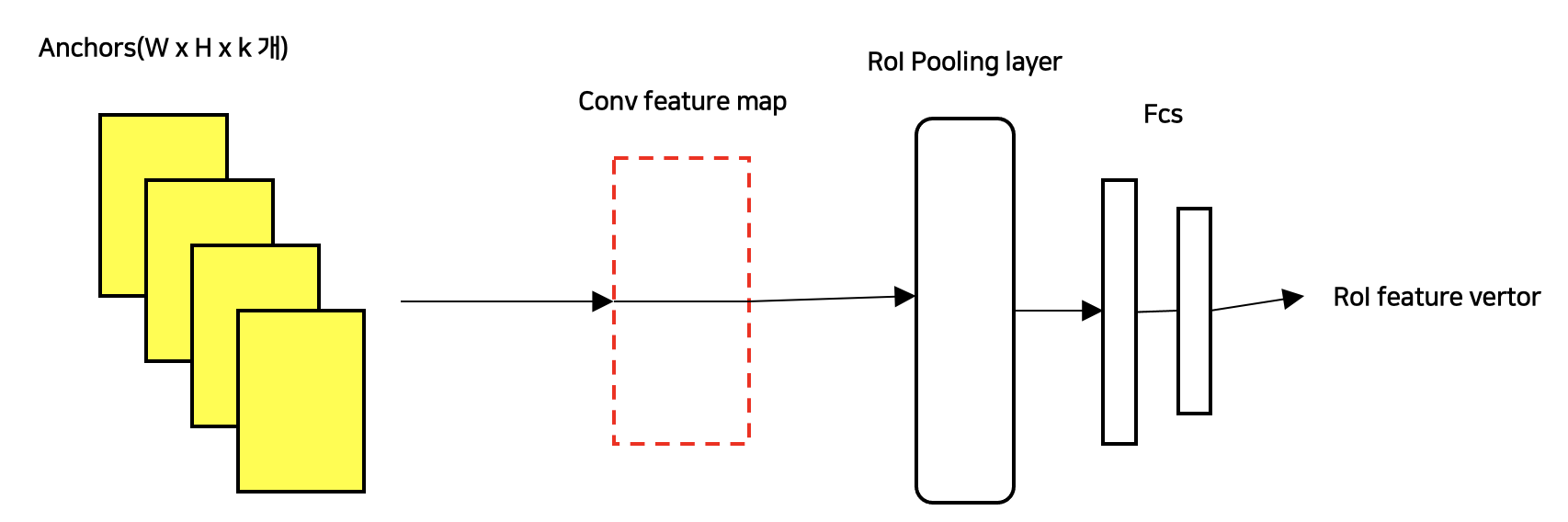
- RPN에서 사용된 전체 이미지에 대한 Conv feature map을 사용하여 ROI pooling을 진행한다.
- Anchors는 원본 이미지의 비율이 아닌 Conv feature map과 동일한 비율을 가지기 때문에 별도의 Projection 과정이 필요 없다.
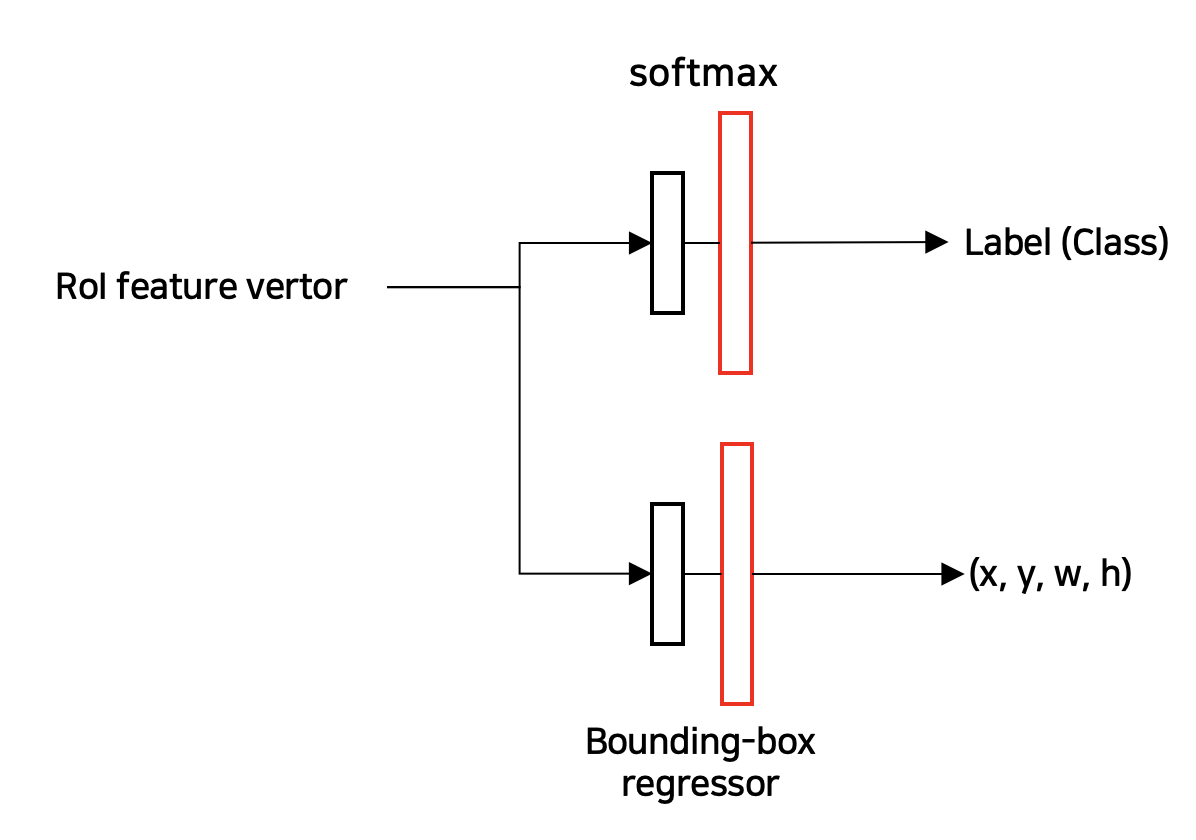
(4) ROI feature vector를 이용한 Classification 및 Bounding box regression 수행
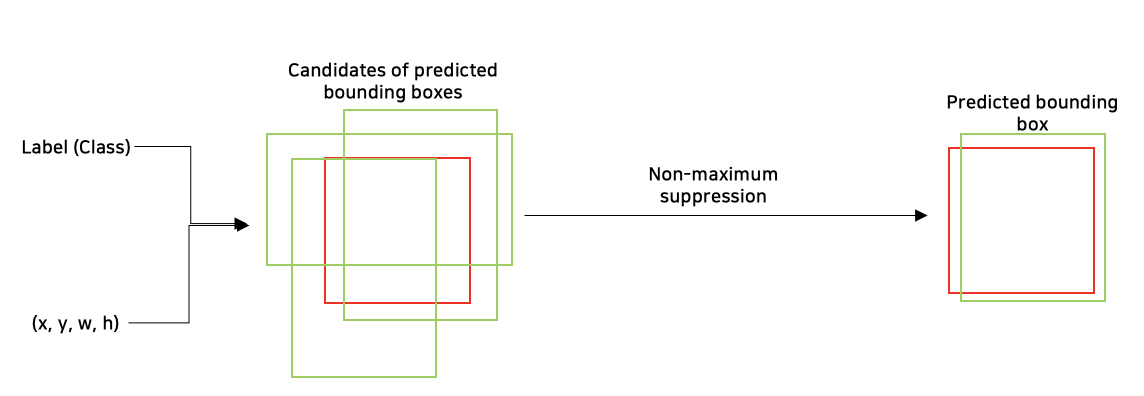
(5) Non-maximum suppresssion을 통한 최종 Predicted bounding box 추론
3) Faster R-CNN의 Training
(1) Faster R-CNN의 Training process
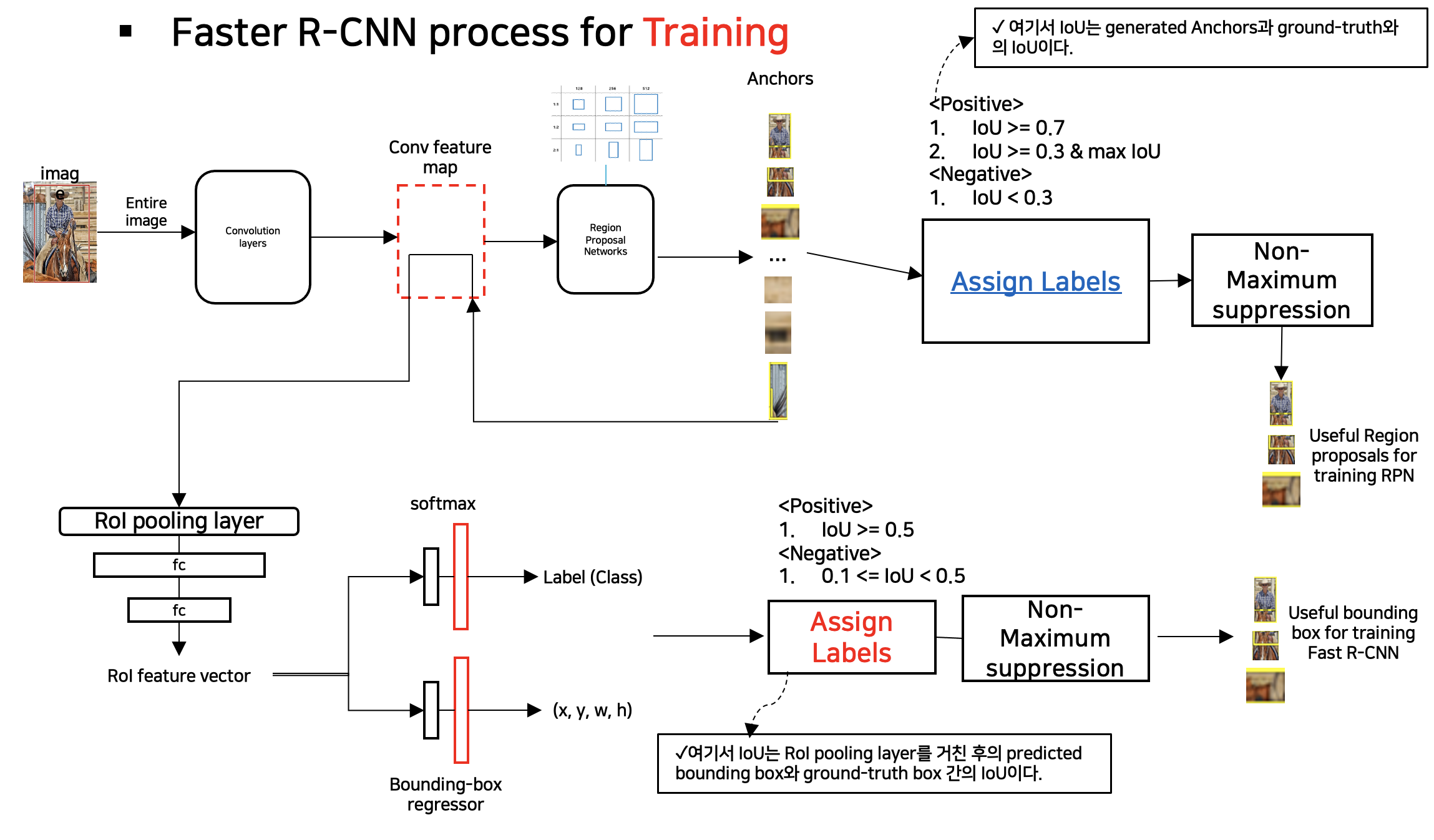
(2) RPN의 Loss function
- RPN Loss function
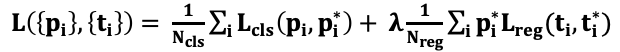
- RPN Loss function의 각 요소별 설명

- RPN Loss function 설명Negative sample(background)에 대해서는 regression을 수행하지 않는다.
- normalization을 수행
- λ와 normalization에 의해 cls와 reg는 대략적으로 비슷하게 weighted 된다.
(3) Bounding box regression
- BBox Loss function
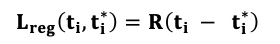
- BBox coordinate 수식 정의
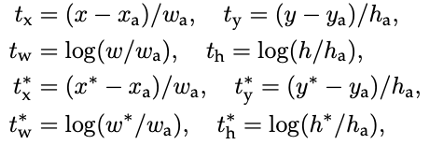
- x, y는 Box의 중심점, w, h는 각각 너비와 높이
- 각 요소 표시방법에 대한 설명

- 수식 해석
-
RPN의 Bounding box regression은 anchor을 ground-truth box에 approximate 하기위한 function이다.
-
즉, positive anchor에 대해 예측한 bounding box와 ground-truth box간의 오차를 구한 것
-
(4) RPN Training의 세부사항
- SGD optimizer를 사용하여 end-to-end로 학습이 진행
- 학습 데이터의 형태는 image-centric sampling을 사용
- 모든 새로운 Layer(RPN, Fast R-CNN)의 가중치는 0.01의 표준편차를 가지는 zero-mean Gaussian distribution에 따라 랜덤하게 초기화
- 모든 다른 layers(shared convolution layers 등)은 ImageNet의 Pre-training Model로 초기화
-
60k mini-batches에 대해서는 0.001의 learning rate를, 20k mini-batches에 대해서는 0.0001의 learning rate를 사용
-
momentum은 0.9, weight decay는 0.0005로 설정
- Caffe library를 사용
(5) RPN과 Fast R-CNN Detector 부분의 feature sharing을 위한 학습방법
본 논문에서 제시한 학습방법은 3가지이며 본문에서는 '1'번의 Alternating training 방법을 사용하였다.
-
Alternating training
-
RPN을 먼저 학습
-
RPN에서 생성한 proposals으로 Fast R-CNN fine-tuning
-
Trained Fast R-CNN으로 RPN fine-tuning
- 위의 과정을 반복한다.
- 해당 방법은 본문에서 Faster R-CNN을 학습할 때 사용된 방법이다.
-
-
Approximate joint training
-
RPN과 Fast R-CNN을 Merge
-
구현은 간단하지만, proposals의 좌표를 무시해서 근사한 결과만 도출된다.
-
학습시간은 Alternating training에 비해 25~50% 빠르다.
-
-
Non-approximate joint training
-
RPN과 Fast R-CNN을 Merge
-
Bounding box의 좌표를 포함하여 학습
-
구현이 어려운 방법으로, 본문에서는 상세하게 다루지 않는다.
-
(6) 4-step Alternating Training
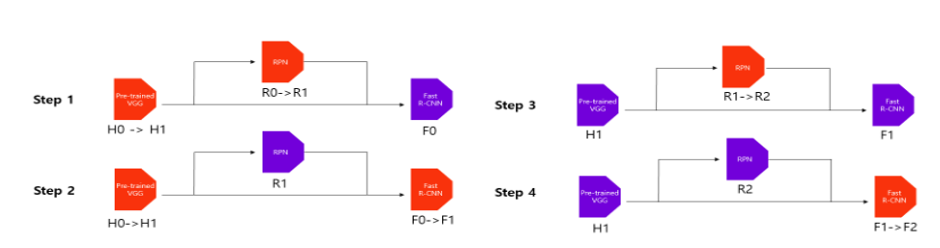
-
ConvNet을 ImageNet(VGG-16 or ZFNet)으로 Pre-train 후 RPN에 대한 fine-tuning을 진행(end-to-end로 전체 Network에 대한 학습이 진행된다)
-
RPN에서 생성한 proposals로 Fast R-CNN fine-tuning
-
Fine-tuned Fast R-CNN을 사용하여 RPN의 Conv layer에 대해서만 fine-tuning
-
Fast R-CNN의 Conv layer에 대해서만 fine-tuning
-
해당 과정을 통해서 전체 이미지에 대한 Conv layer는 고정하기 때문에 RPN과 Fast R-CNN은 해당 Conv layer을 완전히 공유한다.
-
본 과정은 여러 번 수행되어도 상관없지만, 본문에서는 4번으로 충분하다고 함.
-
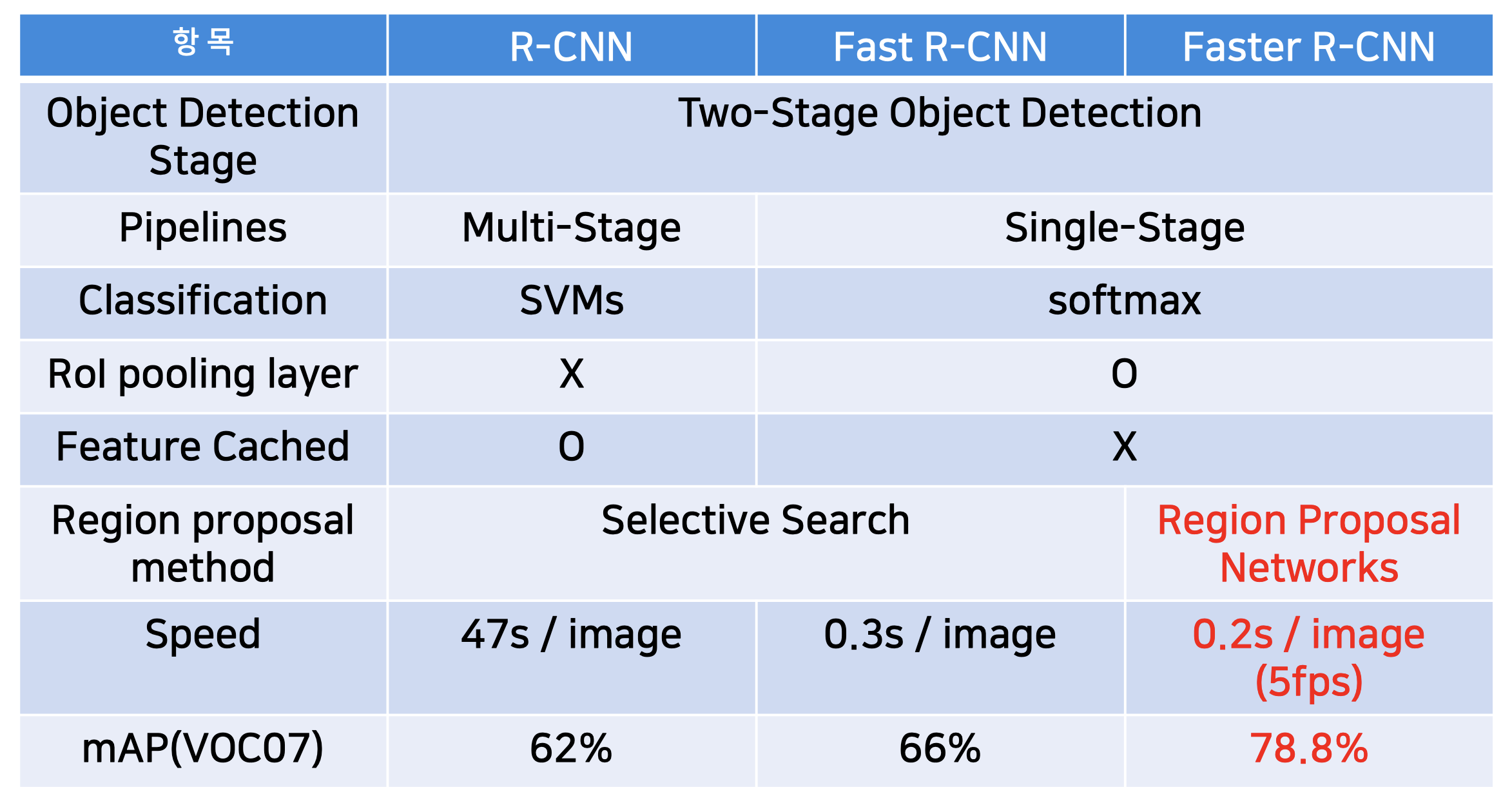
4) R-CNN vs. Fast R-CNN vs. Faster R-CNN
4. 실험
1) Region proposal의 방법에 따른 성능 비교
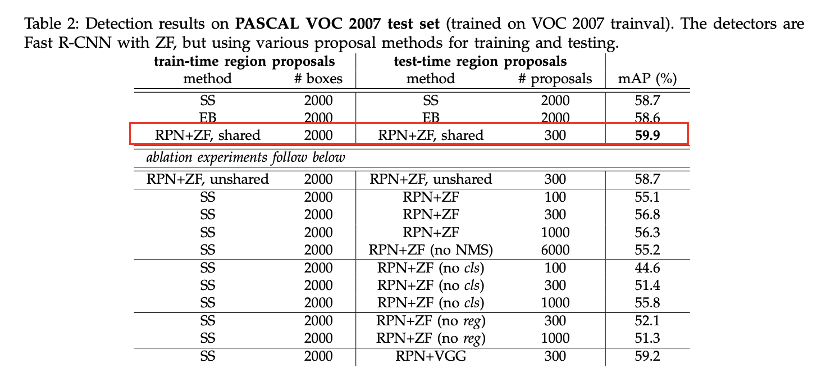
-
RPN + ZF(mini-network의 구성 시 ZFNet 구조 사용) 및 shared convolution feature map의 방법을 train과 test에 동시에 적용했을 때, 가장 성능이 좋았다.
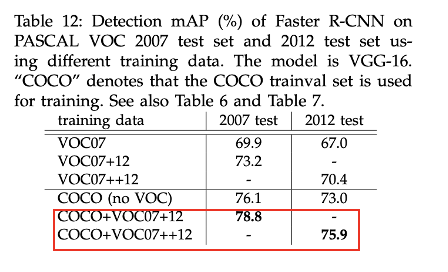
2) Region proposal 방법 및 사용하는 학습 데이터에 따른 성능 비교
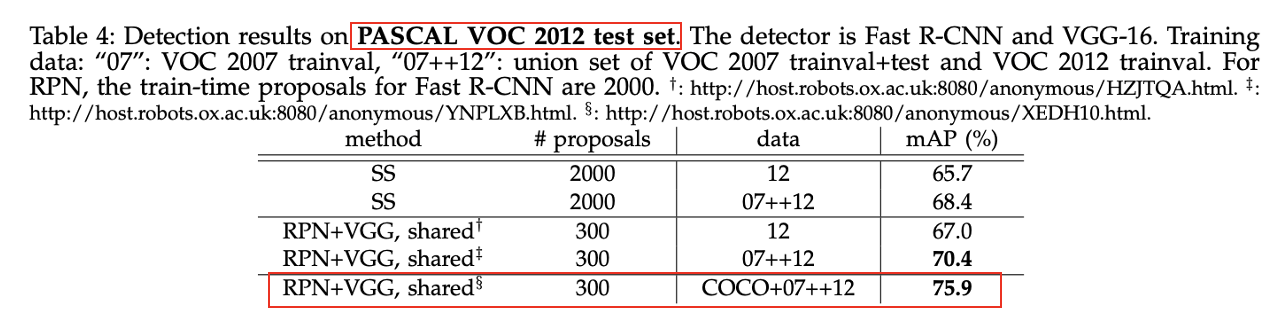
-
PASCAL VOC 2012 test set에 대해서도 VOC 2007 test set과 마찬가지로 RPN+VGG, shared에서 COCO+07+12데이터 셋을 사용한 것이 가장 성능이 좋았다.
3) RPN의 CNN architecture와 Region proposal method에 따른 Object Detection의 속도 비교

-
ZFNet을 RPN의 구조로 사용하고, Region proposal method를 RPN으로 사용하였을 때, 속도가 가장 빨랐다.
4) Anchor box의 scales 및 aspect ratios에 따른 성능 비교
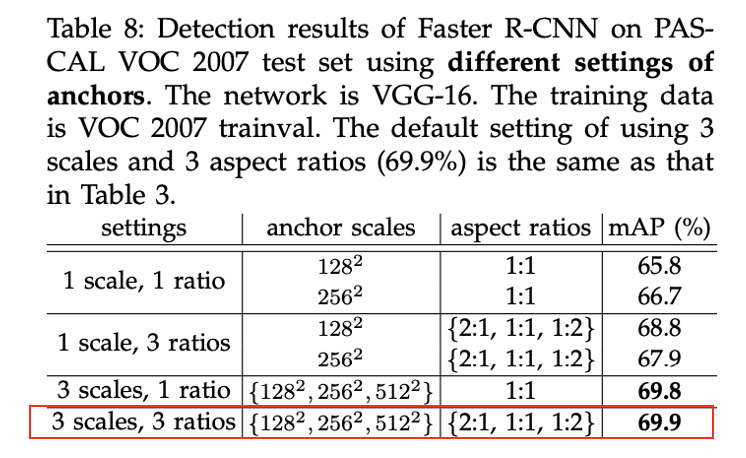
- 3 scales, 3 ratios일 때, 성능이 가장 좋았다.
- Aspect ratios보다는 Scales가 성능에 더 영향을 끼쳤다.
5) λ의 값에 따른 성능 비교

- λ의 값을 10으로 설정했을 때, 가장 성능이 좋지만 λ 값에 대한 변화가 성능에 큰 영향을 끼치지는 않는다.
6) Region proposal method와 proposal의 수에 따른 Recall 및 IOU 값 비교
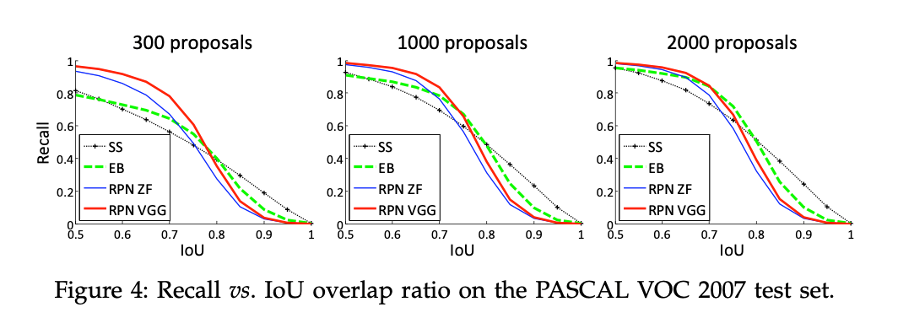
-
RPN을 통한 Region proposal method는 proposals의 수에 Recall이 거의 영향을 받지 않는다.
-
300개의 Proposals로도 좋은 성능을 낸다.
7) One-stage Detecion과 Two-stage Detection의 성능 비교

-
Faster R-CNN에서 RPN을 통해 생성되는 Region proposals는 후에 classification 및 localization의 과정이 따로 수행된다.
-
반면에, 구조에서는 Region proposals와 동시에 classificatOverfeation 및 localization이 수행된다.
-
One-Stage Detection은 빠르지만 mAP는 낮고, Two-Stage는 상대적으로 느리지만 mAP는 높다.
8) MS COCO dataset에서의 성능비교
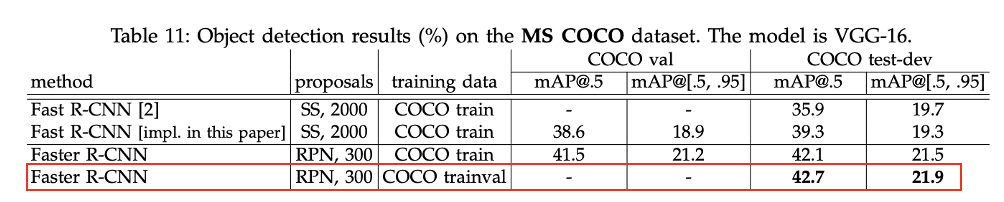
- Faster R-CNN은 MS COCO dataset에 대해서 Fast R-CNN보다 좋은 성능을 냈다.
- 또한 COCO dataset으로 Faster R-CNN을 학습시킨 경우에도 더 좋은 성능을 냈다.
* 부록
A. Region Proposal Network(RPN)
1) 개요
-
Input : 하나의 이미지(사이즈는 관계없음)
-
Output : object proposals의 집합과 각 proposals에 대한 objectness score
-
RPN은 하나의 fully convolution network
- Region proposals(Anchors)를 생성하기 위해서 small network를 convolution feature map과 겹쳐서 slide하는 방식으로 진행한다.
(small network는 n x n spatial window (본문에서 n = 3)을 입력으로 받아 저차원 feature(low-dimensional feature, conv net이 ZFNet인 경우 256-dim, VGG-16인 경우 512-dim)을 생성한다)
2) Region Proposal Network의 Region Proposal 생성
- Anchor Box 참조
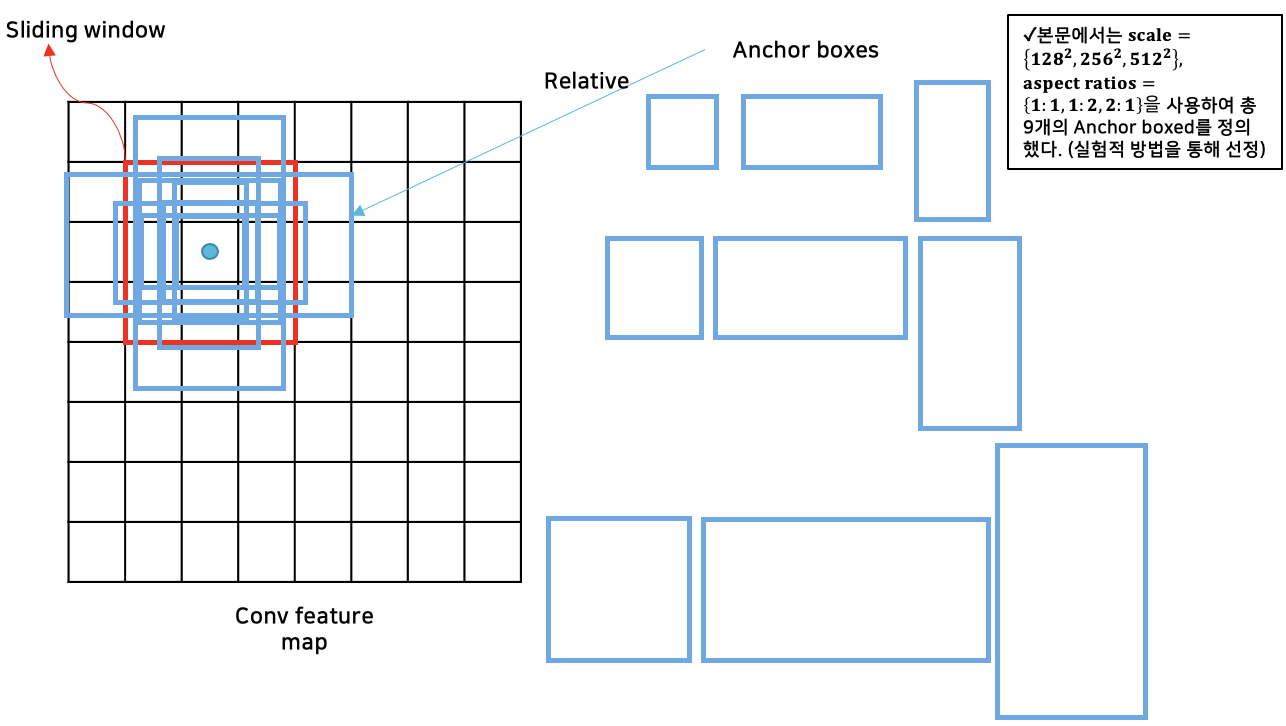
- Window Sliding 및 Region proposal 생성
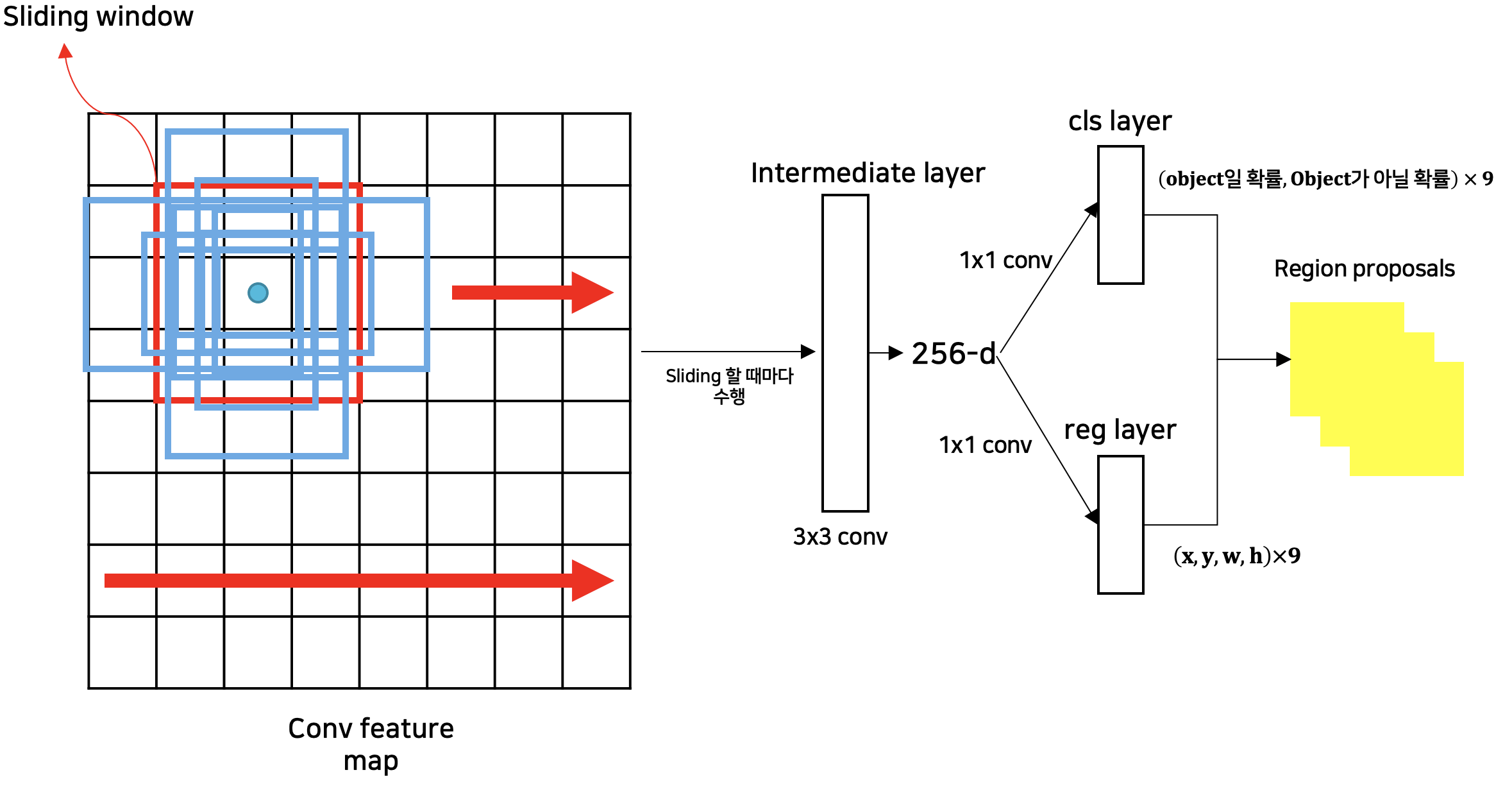
- RPN - Detail (n=3, k=9)
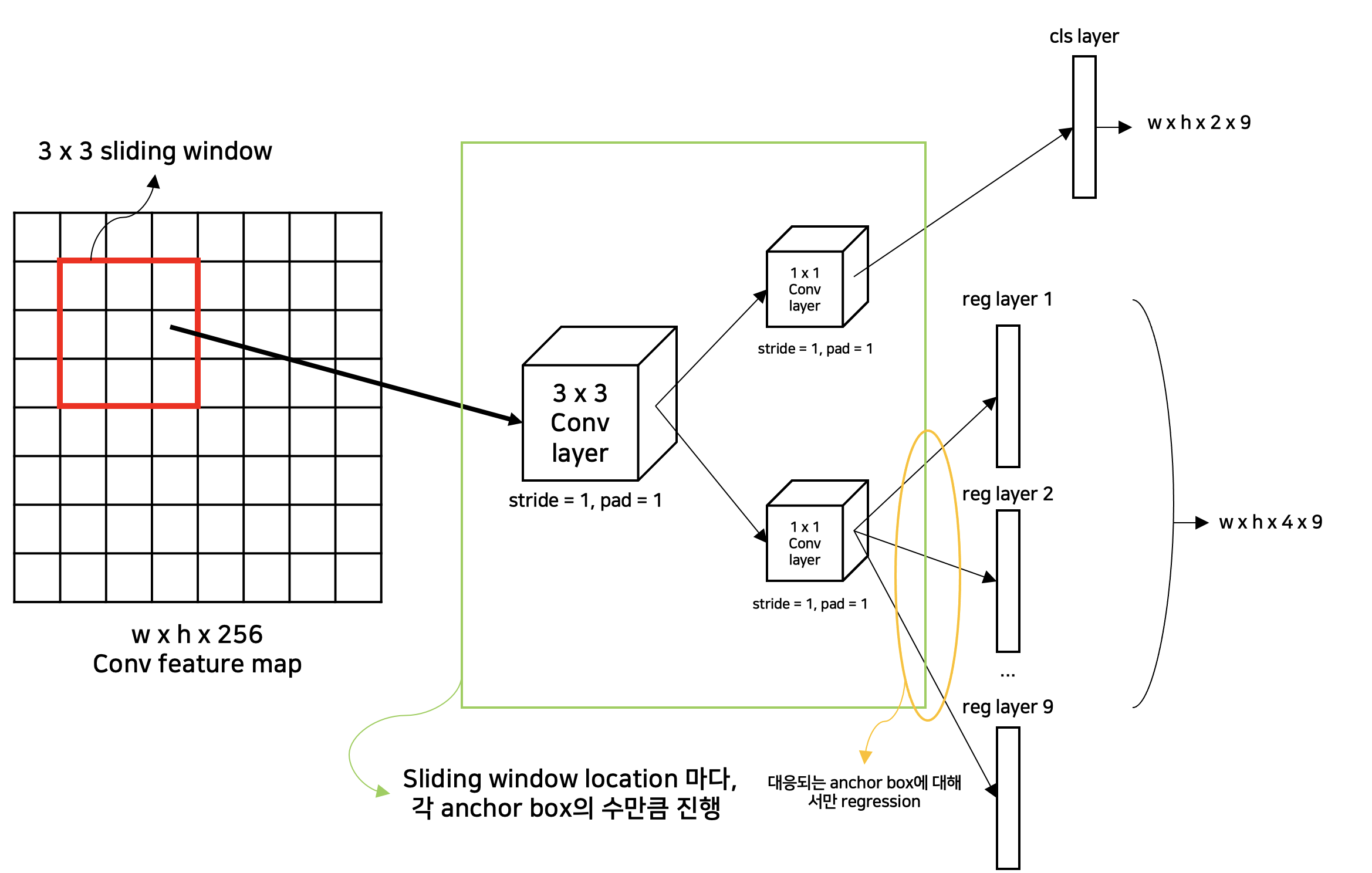
3) RPN 세부 기법
(1) Translation-Invariant을 가지는 Anchors 방법
- Anchors를 이용한 방법은 conv feature map에서 각 window location마다 다양한 scales와 aspect ratios의 Anchor boxes를 사용한 sliding-window 기법을 적용
- 이 방법을 통해서 전체 feature map의 Region proposals을 찾아내기 때문에 Translation-Invariant한 특성을 가진다.
-
즉, 이미지 상에서 Object가 이동하더라도 같은 Region proposals를 추출할 수 있다.
(2) 모델의 크기를 감소시키는 Anchors 기법
-
Multibox model
-
Multibox model은 k-means 알고리즘을 사용하여 800개의 anchors를 생성, 즉, (4(box coordinates) + 1(object probability)) x 800의 fully connected output layer을 가진다.
- 즉, Multibox model의 output layer는 (4 + 1) x 800 x 1536(GoogleNet) = 6.1 × 10^6의 Parameters를 가진다
- feature projection layer을 고려하면, 7 x 7 x (64 + 96 + 64 + 64) x 1536 + 5 x 1536 x 800 = 27 × 10^6의 Parameters를 가진다.
-
-
Region Proposal Network
-
k(anchor box의 수) = 9(본문에서 지정)이라고 했을 때, (4(box coordinates) + 2(object probability, non-object probability)) x 9의 convolution output layer을 가진다.
- 즉, RPN의 output layer는 512(VGG-16 기반에서 수행될 때, low-dimensional feature) x (4 + 2) x 9 = 2.8 × 10^4의 Parameters를 가진다.
-
cls layer, reg layer에 대한 3 x 3 conv layer, 1 x 1 conv layer(feature projection layer)을 고려하면, (3 x 3 x 512) x (1 x 1 x 512) + (4 + 2) x 9 x 512 = 2.4 × 10^6의 Parameters를 가진다.
-
=> 결론적으로, Anchors 기법은 모델의 사이즈를 줄이는 역할도 수행한다.
(3) Regression references 관점의 Multi-scales Anchors
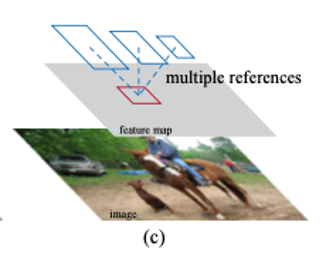
-
Pyramids of anchors 방법을 사용
-
전체적으로 하나의 Input 이미지와 하나의 size를 가진 filter만이 필요
- 따라서 single image에 대한 convolution features 연산과 Fast R-CNN detector에 관한 연산을 간단하게 수행할 수 있다
- 즉, Scale 처리를 위한 추가 비용이 없이 features를 공유하는 중요한 기능적 요소이다.
B. Objectness Scores
1) 개요
-
Faster R-CNN에서 Objectness scores는 generated region proposal(anchor)과 ground-truth box의 IoU이다.
- Object가 있는지, 없는지 즉, Positive인지 Negative인지에 대한 판단을 내릴 때 사용되는 값이다.
-
Faster R-CNN에서는 다음의 기준으로 Positive와 Negative를 판단한다.
- Positive
-
IoU >= 0.7이면, Positive
-
만약 '1'의 조건을 만족하는 anchor가 없다면, IoU >= 0.3인 anchor 중 IoU가 가장 높은 anchor만을 사용하면 특이 cases가 존재하게 되어서 '1'도 병행하여 사용한다.
-
- Negative
- IOU < 0.3이면, Negative
- 단, Positive도 Negative도 아닌 anchor에 대해서는 고려하지 않는다.
- Positive
-
Positive를 판단하는 과정에서 1)의 조건을 통해 한 Ground-truth box에 대해 여러 개의 positive anchor가 존재할 수 있기 때문에, Object Detection시에 non-maximum suppression을 수행한다.
2) 예시
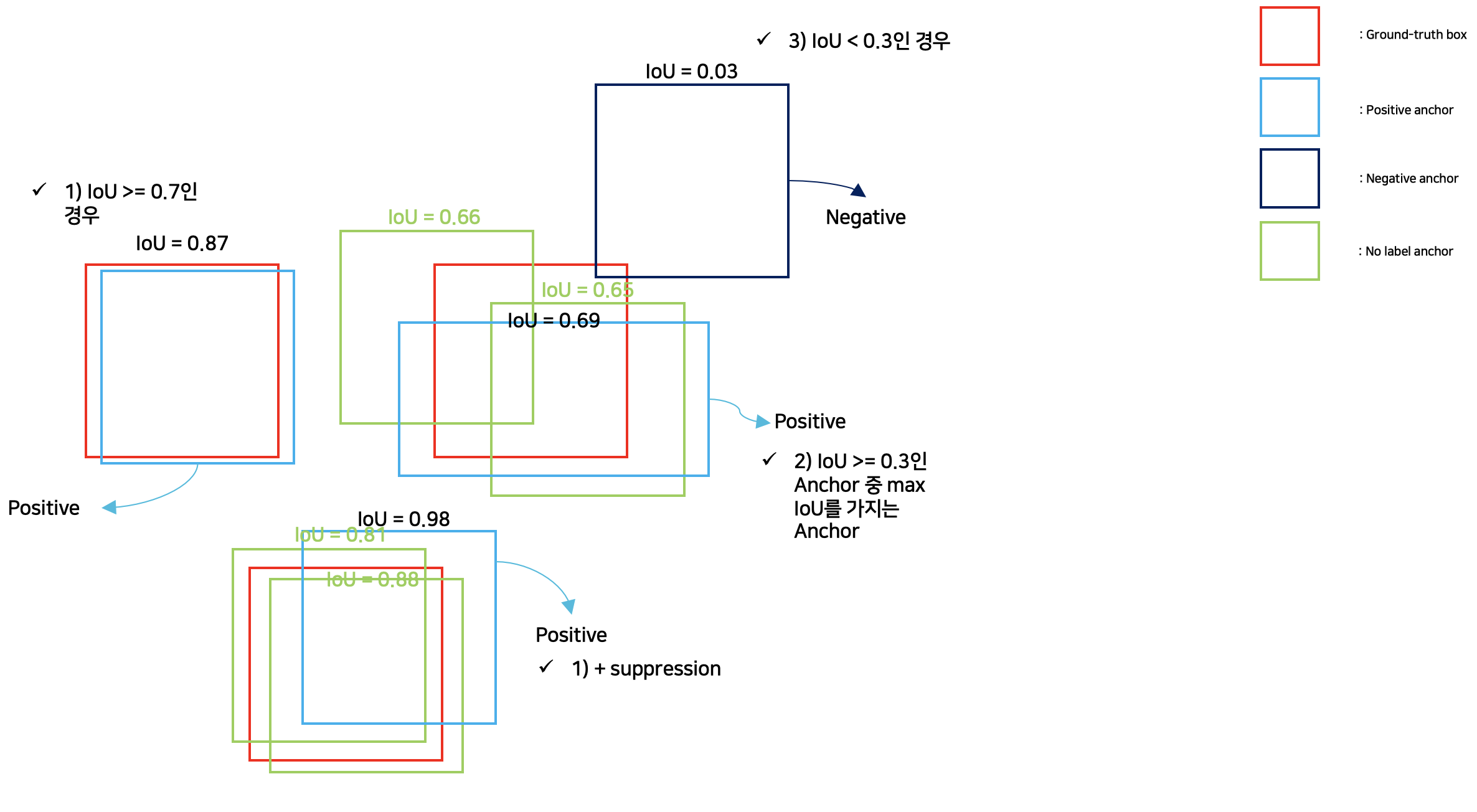
* Reference
[1] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun . Faster R-CNN. IN CSCV, 2016.
[2] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
[3] YouTube - 나동빈. https://www.youtube.com/watch?v=46SjJbUcO-c&t=136s
[4] Blog - Ankur Mohan. https://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
'Paper Review > Object Detection' 카테고리의 다른 글
| [Paper Review - Object Detection] 6. YOLOv3 : An Incremental Improvement (0) | 2023.02.26 |
|---|---|
| [Paper Review - Object Detection] 5. YOLO9000 : Better, Faster, Stronger (0) | 2023.02.13 |
| [Paper Review - Object Detection] 4. YOLOv1 (0) | 2023.01.25 |
| [Paper Review - Object Detection] 2. Fast R-CNN (0) | 2023.01.15 |
| [Paper Review - Object Detection] 1. R-CNN (0) | 2023.01.10 |



